Classificação Antifraude em Seguros Automotivos usando Funções Discriminantes Lineares e Quadráticas
1 Contexto e Objetivo
Uma seguradora de automóveis quer automatizar a triagem de sinistros para decidir quais casos devem ser auditados com prioridade (investigação antifraude). Historicamente, o setor antifraude classifica sinistros em:
Classe A (Regular): sinistro com perfil compatível com o padrão esperado.
Classe B (Suspeito): sinistro com padrão atípico (alto risco de inconsistência/fraude).
Para cada sinistro, são coletadas variáveis operacionais e comportamentais:
valor_reparo (R$)
dias_para_reportar: dias entre o evento e o aviso
qt_sinistros_12m: nº de sinistros nos últimos 12 meses
ratio_reparo_vs_fipe: valor reparo / valor FIPE do veículo
dist_evento_resid: km entre local do evento e residência
mudancas_contato_6m: nº de mudanças de telefone/endereço nos últimos 6 meses
O objetivo desta análise é usar Análise Discriminante para classificar sinistros como Regular vs Suspeito e justificar quando usar LDA e quando usar QDA, comparando desempenho e suposições.
valor_reparo dias_para_reportar qt_sinistros_12m ratio_reparo_vs_fipe
Min. : 2731 Min. : 1.229 Min. :0.0000 Min. :0.02225
1st Qu.: 6336 1st Qu.: 5.304 1st Qu.:0.0000 1st Qu.:0.31351
Median : 7995 Median : 7.223 Median :1.0000 Median :0.48738
Mean : 8449 Mean : 7.890 Mean :0.8025 Mean :0.53469
3rd Qu.: 9553 3rd Qu.: 9.758 3rd Qu.:1.0000 3rd Qu.:0.70367
Max. :26571 Max. :19.550 Max. :5.0000 Max. :1.46809
dist_evento_resid mudancas_contato_6m classe
Min. : 2.682 Min. :0.0000 Regular :320
1st Qu.: 15.873 1st Qu.:0.0000 Suspeito: 80
Median : 25.454 Median :0.0000
Mean : 29.362 Mean :0.5125
3rd Qu.: 37.239 3rd Qu.:1.0000
Max. :134.776 Max. :4.0000
A inspeção inicial dos dados indica que as variáveis apresentam escalas distintas e distribuições assimétricas positivas, especialmente para valor_reparo e dist_evento_resid, cujos valores máximos são substancialmente superiores às medianas. As variáveis qt_sinistros_12m e mudancas_contato_6m assumem valores inteiros baixos, sugerindo natureza discreta de contagem. Observa-se ainda desbalanceamento entre as classes, com predominância da categoria Regular. Nesta etapa, entretanto, não é possível inferir diferenças estruturais entre as populações, sendo necessária análise estratificada por classe.
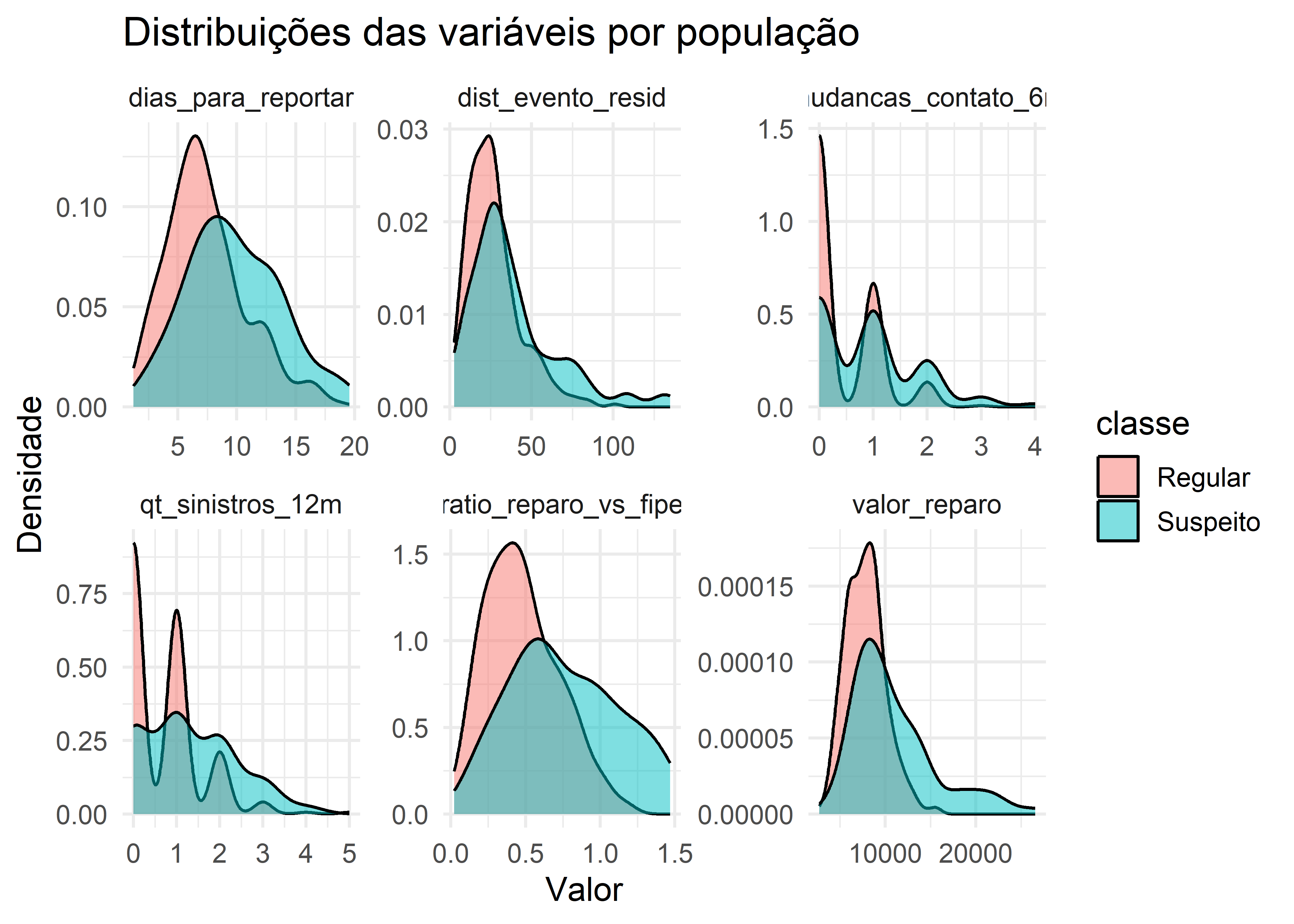
df_long <- df %>%pivot_longer(-classe, names_to ="variavel", values_to ="valor")ggplot(df_long, aes(x = valor, fill = classe)) +geom_density(alpha =0.5) +facet_wrap(~ variavel, scales ="free", ncol =3) +theme_minimal(base_size =13) +labs(title ="Distribuições das variáveis por população",x ="Valor", y ="Densidade")
A análise das distribuições das variáveis por população indica diferenças consistentes no comportamento das duas classes. Observa-se que a população Suspeito apresenta deslocamento das densidades para valores mais elevados em variáveis como dias_para_reportar, ratio_reparo_vs_fipe, qt_sinistros_12m e valor_reparo, além de maior dispersão geral, sugerindo maior heterogeneidade nesses casos. Em dist_evento_resid, a distribuição dos suspeitos apresenta cauda mais longa, indicando ocorrência relativamente mais frequente de valores extremos. Já a variável mudancas_contato_6m mostra concentração em valores baixos para ambas as populações, embora o grupo Suspeito apresente maior variabilidade. Apesar dessas diferenças, observa-se sobreposição considerável entre as densidades das duas classes em praticamente todas as variáveis, indicando que a separação entre Regular e Suspeito não é trivial quando analisada isoladamente em cada variável, reforçando a necessidade de métodos multivariados para identificação conjunta dos padrões discriminantes.
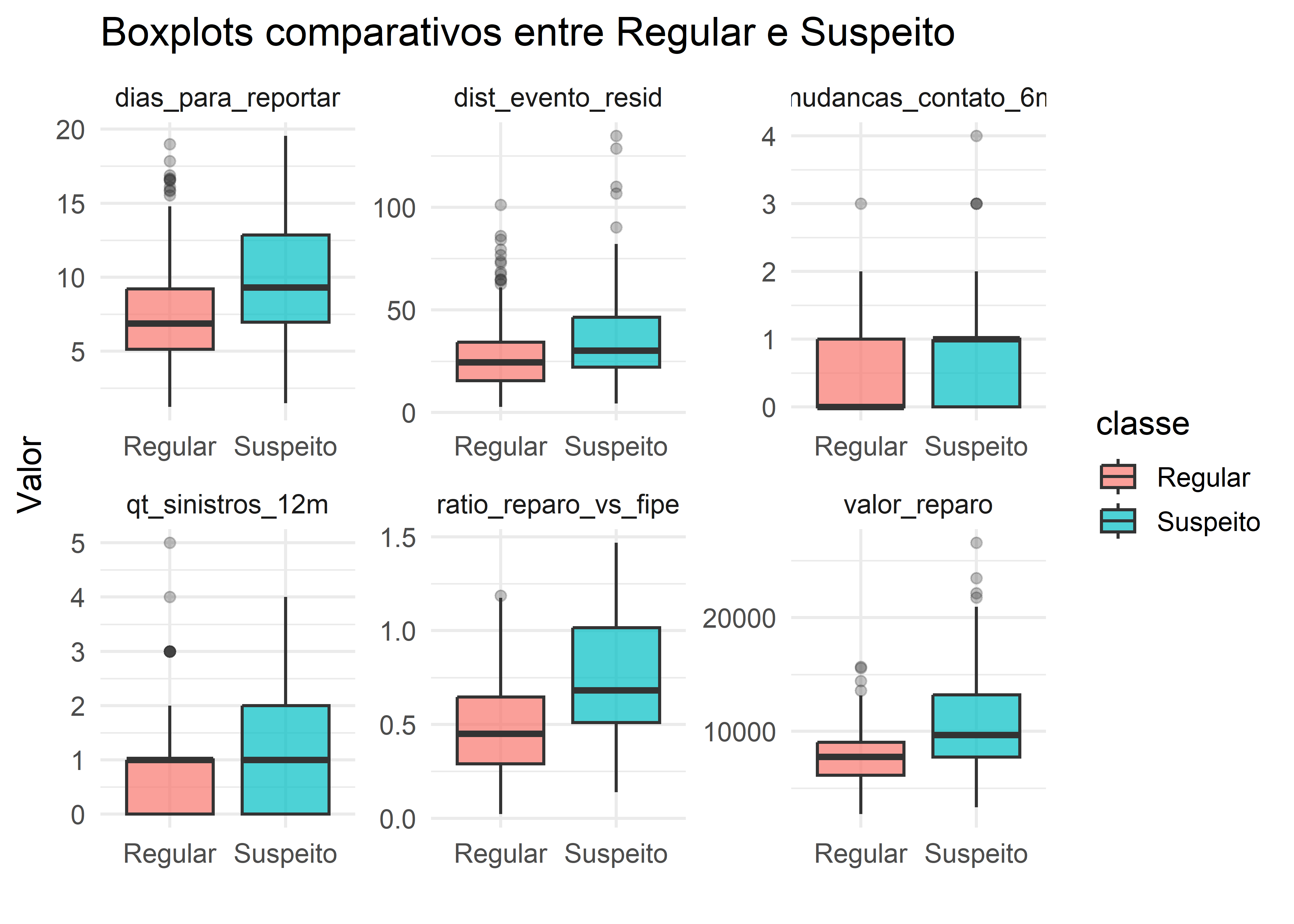
ggplot(df_long, aes(x = classe, y = valor, fill = classe)) +geom_boxplot(alpha =0.7, outlier.alpha =0.3) +facet_wrap(~ variavel, scales ="free", ncol =3) +theme_minimal(base_size =13) +labs(title ="Boxplots comparativos entre Regular e Suspeito",x ="", y ="Valor")
Os boxplots comparativos evidenciam diferenças consistentes entre as populações Regular e Suspeito em diversas variáveis analisadas. Observa-se que a classe Suspeito tende a apresentar medianas mais elevadas e maior dispersão em dias_para_reportar, dist_evento_resid, qt_sinistros_12m, ratio_reparo_vs_fipe e valor_reparo, indicando maior variabilidade e presença mais frequente de valores extremos nesses casos. A variável mudancas_contato_6m apresenta distribuição concentrada em valores baixos para ambas as populações, embora o grupo Suspeito mostre maior amplitude interquartílica. Apesar das diferenças nas tendências centrais e na variabilidade, verifica-se sobreposição entre os intervalos interquartílicos das duas classes, sugerindo que nenhuma variável isoladamente é suficiente para uma separação completa entre os grupos, reforçando a necessidade de abordagem multivariada para fins de classificação.
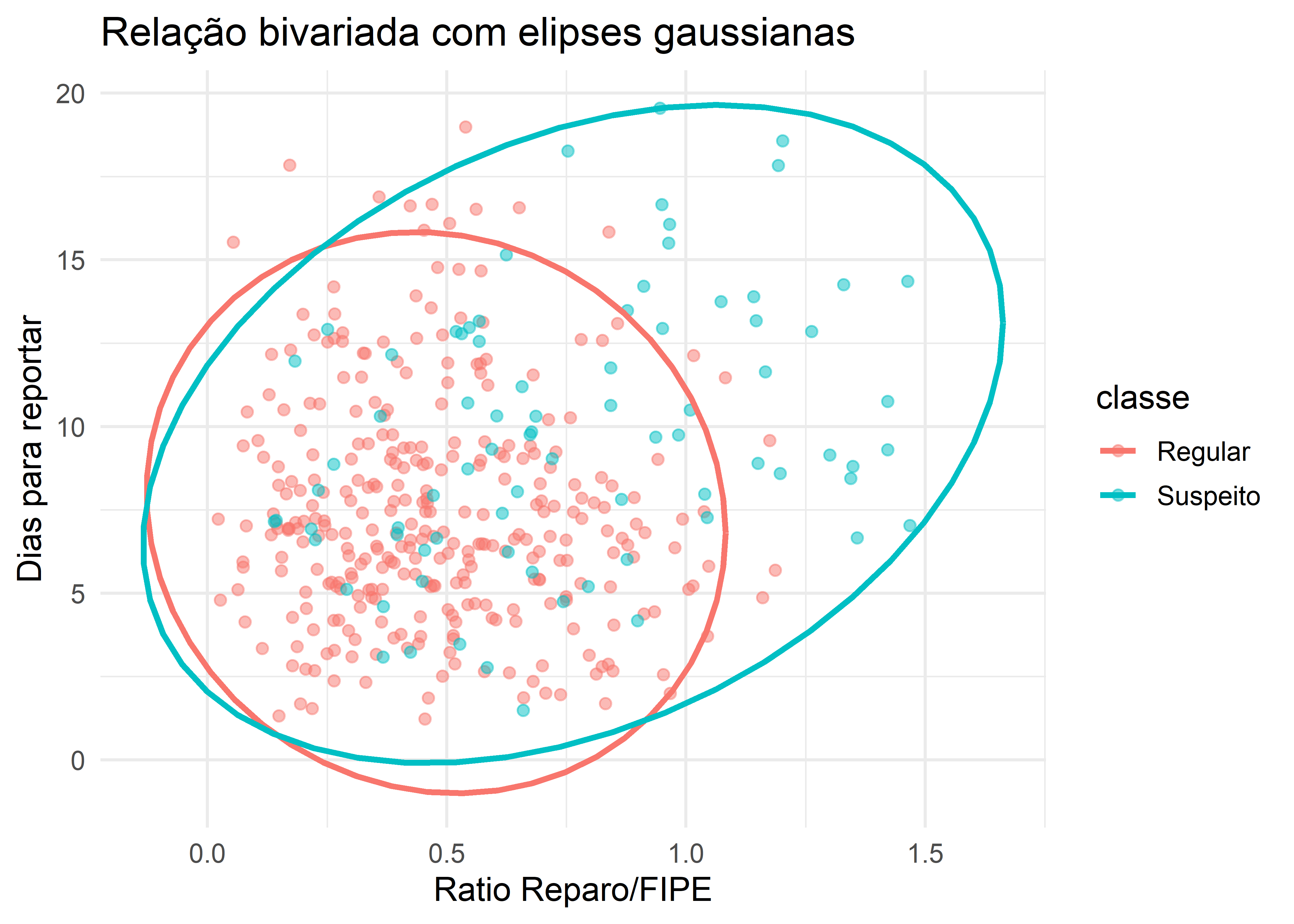
A análise da relação bivariada entre ratio_reparo_vs_fipe e dias_para_reportar, representada por meio de elipses gaussianas, indica diferenças na posição e na dispersão das duas populações. Observa-se que a classe Suspeito apresenta maior variabilidade conjunta e uma tendência a valores mais elevados em ambas as variáveis, refletida por uma elipse mais ampla e deslocada em relação ao grupo Regular. Além disso, a orientação distinta das elipses sugere padrões de associação diferentes entre as variáveis nas duas classes. Apesar dessas diferenças estruturais, verifica-se uma região considerável de sobreposição entre os grupos, indicando que a separação não é linearmente perfeita quando analisada apenas nesse plano bidimensional, o que reforça a necessidade de métodos multivariados para capturar adequadamente a estrutura discriminante dos dados.
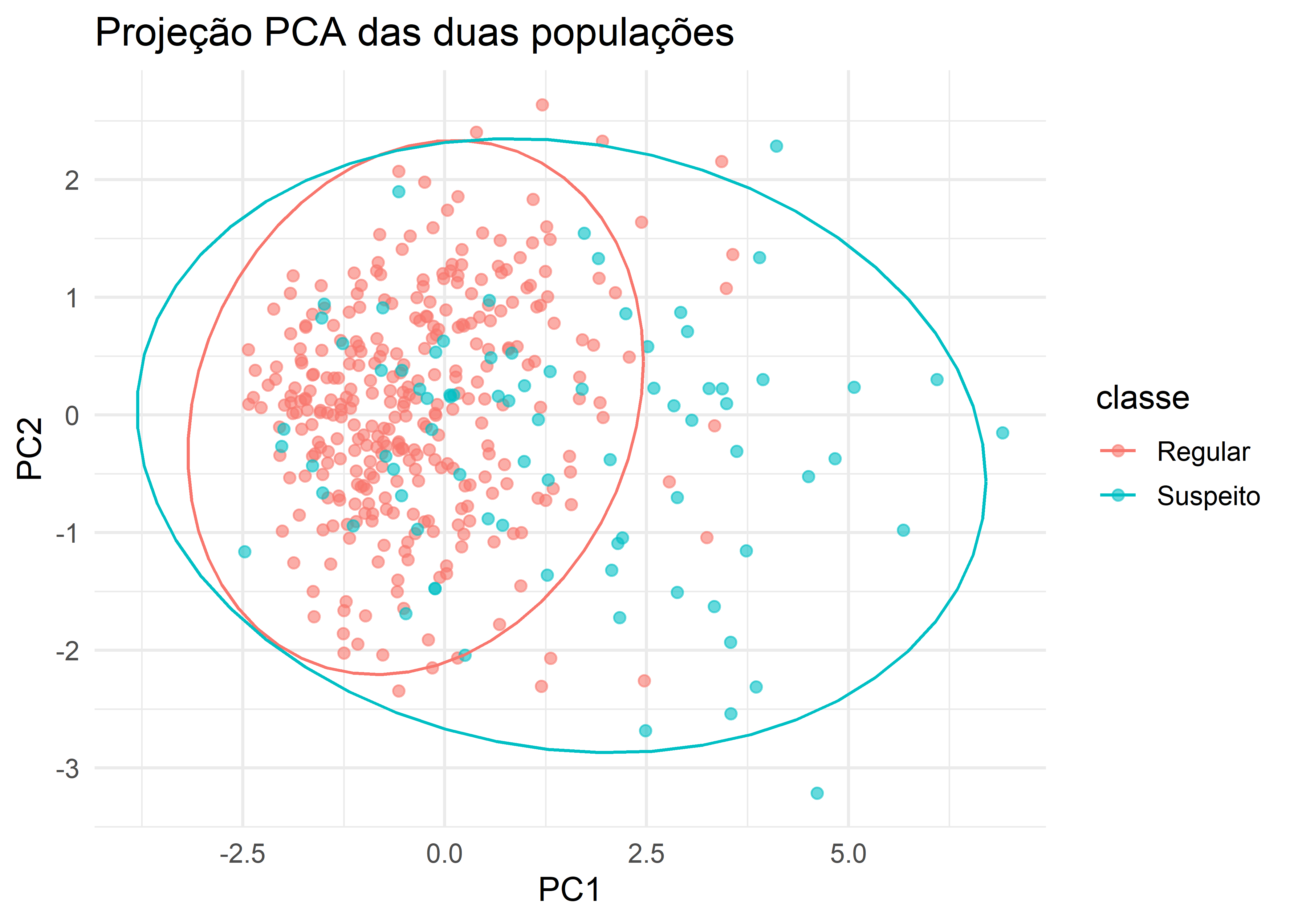
X_scaled <-scale(df[, -7])pca <-prcomp(X_scaled)pca_df <-data.frame(pca$x[,1:2], classe = df$classe)ggplot(pca_df, aes(PC1, PC2, color = classe)) +geom_point(alpha =0.6) +stat_ellipse(type ="norm") +theme_minimal(base_size =13) +labs(title ="Projeção PCA das duas populações",x ="PC1", y ="PC2")
A projeção das observações nos dois primeiros componentes principais evidencia diferenças estruturais entre as populações analisadas. Observa-se que a classe Suspeito apresenta maior dispersão ao longo do primeiro componente (PC1), indicando maior variabilidade multivariada nesse grupo, enquanto a classe Regular se concentra mais próxima do centro da distribuição. As elipses gaussianas mostram deslocamento dos centróides entre as classes, sugerindo diferenças sistemáticas no padrão conjunto das variáveis. Contudo, a presença de uma região relevante de sobreposição entre as populações indica que a separação não é completamente evidente apenas na projeção bidimensional da PCA, reforçando a necessidade de métodos discriminantes supervisionados para melhorar a capacidade de classificação.
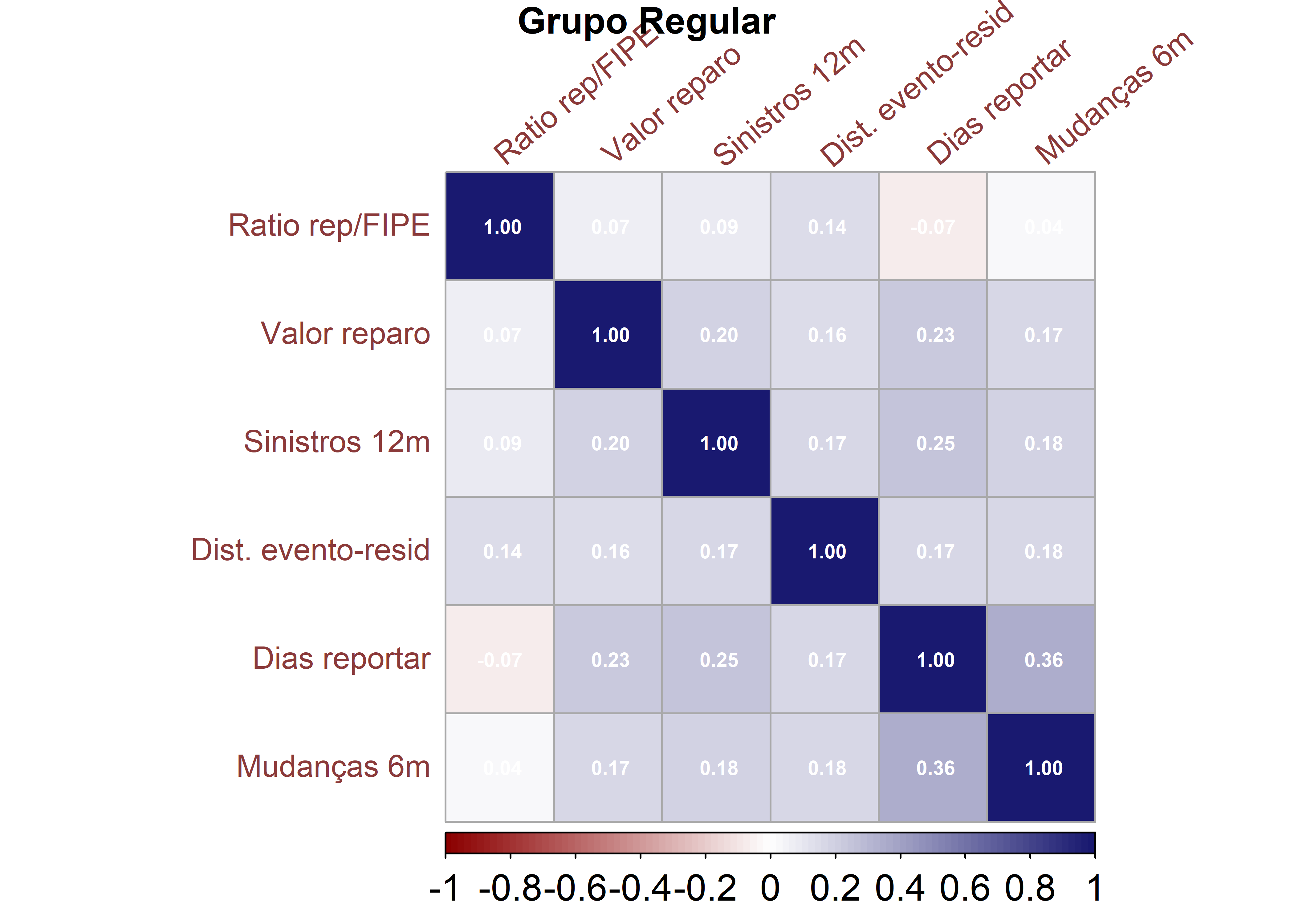
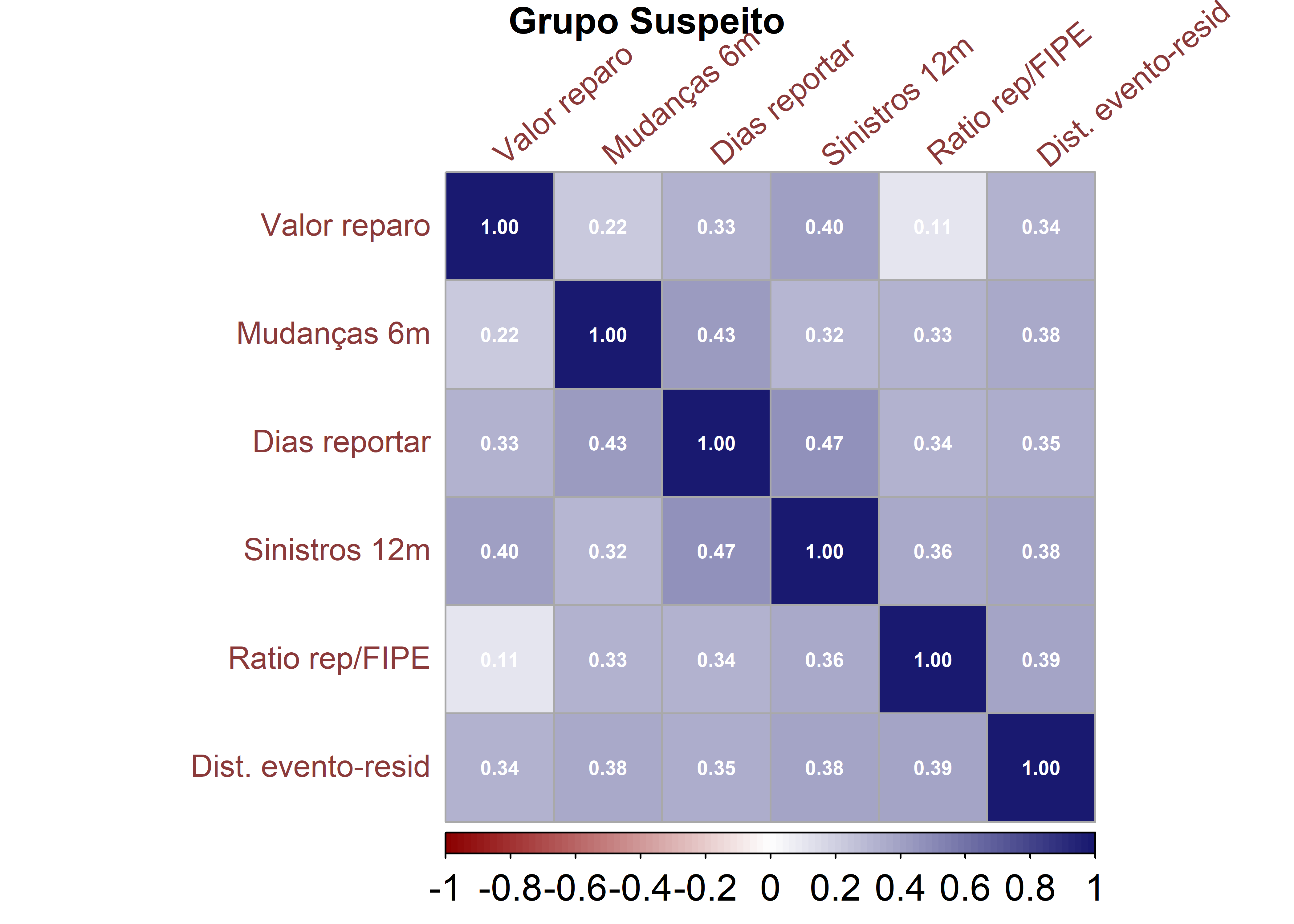
corrplot(corr_sus, method ="color", outline = T, addgrid.col ="darkgray", order ="hclust", cl.pos ="b", tl.col ="indianred4", tl.cex =1.0, tl.srt =40, cl.cex =1.2, addCoef.col ="white", number.digits =2, number.cex =0.65, col =colorRampPalette(c("darkred","white","midnightblue"))(100))mtext("Grupo Suspeito", side =3, line =3, cex =1.2, font =2)
A análise das matrizes de correlação evidencia diferenças importantes na estrutura de dependência entre as variáveis nos dois grupos analisados. No grupo Regular, observa-se um padrão de correlações predominantemente fracas a moderadas, indicando relações lineares pouco intensas entre os indicadores operacionais. As associações entre valor do reparo, sinistros e distância do evento são positivas, porém de baixa magnitude, sugerindo um comportamento relativamente estável e homogêneo dos registros. A variável dias para reportar apresenta correlações discretas com as demais, o que indica que o tempo de comunicação do sinistro não está fortemente ligado às demais características nesse grupo.
Por outro lado, o grupo Suspeito apresenta uma estrutura de correlação mais intensa e consistente entre diversas variáveis. Observa-se associação positiva moderada entre sinistros, dias para reportar, mudanças de contato e distância do evento, sugerindo que esses fatores tendem a aumentar conjuntamente. Esse padrão indica maior interdependência entre os indicadores comportamentais e operacionais, possivelmente refletindo perfis menos homogêneos e maior variabilidade estrutural.
De forma geral, as diferenças entre as matrizes sugerem que os grupos não apenas diferem em nível médio das variáveis, mas também em sua estrutura interna de covariância. Essa evidência reforça a presença de heterogeneidade multivariada entre as populações, aspecto relevante para técnicas de classificação e análise discriminante.
Box's M-test for Homogeneity of Covariance Matrices
data: df[, -7]
Chi-Sq (approx.) = 175.44, df = 21, p-value < 2.2e-16
O teste de Box (Box’s M) foi aplicado para avaliar a homogeneidade das matrizes de covariância entre os grupos. O resultado obtido (\(\chi^2 = 175.44\), \(gl = 21\), \(p < 2.2 \times 10^{-16}\)) indica rejeição da hipótese nula de igualdade das matrizes, sugerindo que as populações apresentam estruturas de variabilidade distintas. Contudo, deve-se interpretar esse resultado com cautela, pois o teste de Box é altamente sensível ao tamanho amostral e a desvios de normalidade multivariada, podendo detectar diferenças estatisticamente significativas mesmo quando as discrepâncias práticas são moderadas. Ainda assim, a evidência aponta que a suposição de covariâncias iguais, fundamental para a Análise Discriminante Linear, pode estar violada, o que, do ponto de vista teórico, favorece o uso de modelos mais flexíveis, como a Análise Discriminante Quadrática. Assim, a escolha do modelo discriminante deve considerar não apenas o resultado do teste formal, mas também o desempenho preditivo e a estabilidade das classificações obtidas.
As matrizes de covariância estimadas para os grupos Regular e Suspeito indicam diferenças estruturais importantes tanto nas variâncias individuais das variáveis quanto nas relações de dependência entre elas.
Observa-se que o grupo Suspeito apresenta variâncias substancialmente maiores em diversas variáveis, especialmente em valor_reparo e dist_evento_resid, evidenciando maior dispersão e heterogeneidade dos dados nesse grupo. Esse comportamento sugere maior variabilidade operacional e possível presença de casos extremos ou padrões menos homogêneos quando comparados ao grupo Regular.
Além disso, as covariâncias no grupo Suspeito tendem a assumir magnitudes mais elevadas, indicando relações lineares mais intensas entre algumas variáveis, como entre valor_reparo, dias_para_reportar e dist_evento_resid. Já no grupo Regular, as covariâncias são relativamente menores, refletindo uma estrutura mais estável e menos dispersa.
Essas diferenças estruturais reforçam a evidência de que as populações possuem padrões de variabilidade distintos, o que implica que métodos de classificação que assumem igualdade das matrizes de covariância podem não ser plenamente adequados. A presença de heterogeneidade nas estruturas de dispersão sugere que abordagens mais flexíveis, capazes de acomodar diferentes geometrias entre grupos, podem representar melhor a separação entre as classes.
A análise discriminante linear foi ajustada considerando probabilidades a priori de 0,8 para o grupo Regular e 0,2 para o grupo Suspeito, refletindo o desbalanceamento observado entre as classes. As médias padronizadas indicam que o grupo Suspeito apresenta valores sistematicamente mais elevados em todas as variáveis analisadas, sugerindo um perfil geral de maior intensidade operacional e maior exposição ao risco quando comparado ao grupo Regular.
Os coeficientes da função discriminante (LD1) mostram que ratio_reparo_vs_fipe e valor_reparo possuem maior contribuição para a separação entre os grupos, seguidos por dias_para_reportar e mudancas_contato_6m. Já dist_evento_resid e qt_sinistros_12m apresentam influência relativamente menor na combinação linear discriminante. Como todas as variáveis foram padronizadas previamente, a magnitude dos coeficientes pode ser interpretada diretamente como medida de importância relativa na discriminação.
De forma geral, a função discriminante construída sugere que a separação entre as classes ocorre principalmente ao longo de um eixo associado a maiores valores de reparo e maior proporção entre custo de reparo e valor de mercado do veículo, indicando que essas características são fundamentais para distinguir os perfis analisados.
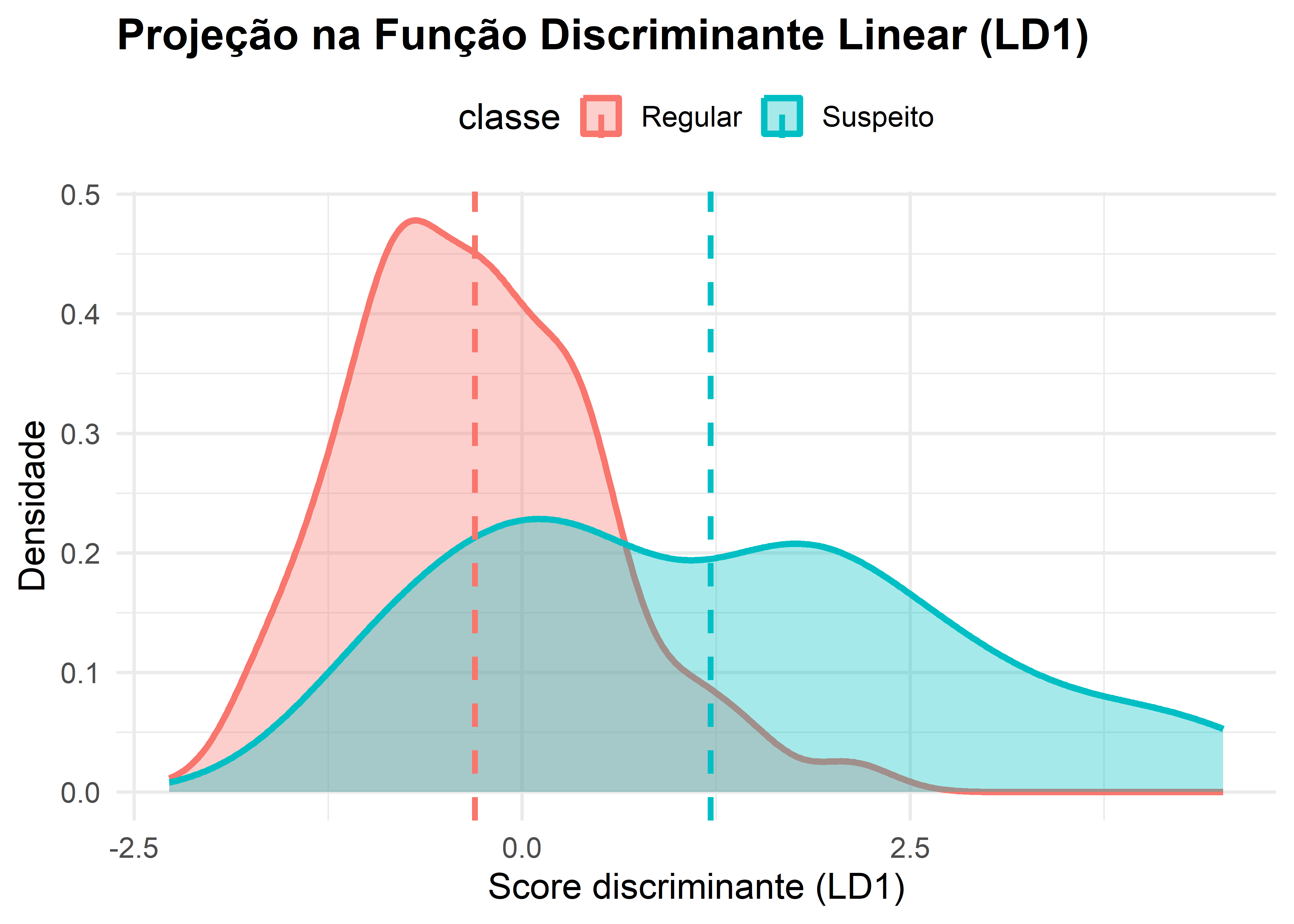
# Obter projeções LD1lda_proj <-predict(fit_lda)$xdados_plot <- df %>%mutate(LD1 = lda_proj[,1])# --------------------------------------------------# Gráfico das densidades na direção discriminante# --------------------------------------------------ggplot(dados_plot, aes(x = LD1, fill = classe, color = classe)) +geom_density(alpha =0.35, linewidth =1.2) +geom_vline(data = dados_plot %>%group_by(classe) %>%summarise(m =mean(LD1)),aes(xintercept = m, color = classe),linetype ="dashed",linewidth =1.1 ) +labs(title ="Projeção na Função Discriminante Linear (LD1)",x ="Score discriminante (LD1)",y ="Densidade" ) +theme_minimal(base_size =14) +theme(plot.title =element_text(face ="bold"),legend.position ="top" )
A projeção dos indivíduos na primeira função discriminante linear (LD1) evidencia uma separação consistente entre os grupos Regular e Suspeito. Observa-se que o grupo Regular concentra-se predominantemente em valores menores do escore discriminante, enquanto o grupo Suspeito apresenta distribuição deslocada para valores mais altos, indicando que a combinação linear das variáveis consegue capturar diferenças estruturais entre as populações. Apesar da sobreposição parcial das densidades, esperada em problemas reais de classificação, as médias dos grupos encontram-se bem separadas ao longo do eixo LD1, sugerindo bom poder discriminante do modelo linear e indicando que a maior parte da variabilidade relevante para a distinção entre as classes está concentrada nessa única dimensão.
Confusion Matrix and Statistics
Reference
Prediction Regular Suspeito
Regular 309 40
Suspeito 11 40
Accuracy : 0.8725
95% CI : (0.8358, 0.9036)
No Information Rate : 0.8
P-Value [Acc > NIR] : 9.165e-05
Kappa : 0.5389
Mcnemar's Test P-Value : 8.826e-05
Sensitivity : 0.5000
Specificity : 0.9656
Pos Pred Value : 0.7843
Neg Pred Value : 0.8854
Prevalence : 0.2000
Detection Rate : 0.1000
Detection Prevalence : 0.1275
Balanced Accuracy : 0.7328
'Positive' Class : Suspeito
A avaliação do desempenho da função discriminante linear indica acurácia global de 87,25%, superior à taxa de classificação pelo acaso (No Information Rate = 0,80), com evidência estatística significativa (p < 0,001). Observa-se elevada especificidade (0,9656), indicando forte capacidade do modelo em identificar corretamente indivíduos da classe Regular. Entretanto, a sensibilidade foi moderada (0,50), sugerindo maior dificuldade na detecção de casos suspeitos, refletida pela presença de falsos negativos. O valor de Kappa igual a 0,5389 indica concordância moderada entre predições e classes reais. A acurácia balanceada (0,7328) evidencia que o desempenho não é uniforme entre as classes, possivelmente influenciado pelo desbalanceamento amostral e pela sobreposição parcial das distribuições. Em termos práticos, o modelo apresenta bom desempenho geral, mas pode requerer ajustes caso a prioridade seja maximizar a identificação de perfis suspeitos.
A análise discriminante quadrática utiliza as mesmas médias por grupo, porém permite matrizes de covariância específicas para cada classe. Considerando que o teste de Box indicou rejeição da hipótese de homogeneidade das covariâncias e que o grupo Suspeito apresenta maior variabilidade estrutural, o modelo QDA é teoricamente mais adequado para representar a separação entre as populações.
Enquanto o LDA produz uma fronteira de decisão linear, o QDA permite superfícies de decisão curvas, capazes de capturar diferenças na dispersão dos grupos. Dado o padrão observado nas matrizes de correlação e covariância, especialmente a maior intensidade das associações no grupo Suspeito, espera-se que o QDA apresente melhor desempenho preditivo em validações fora da amostra.
Confusion Matrix and Statistics
Reference
Prediction Regular Suspeito
Regular 302 38
Suspeito 18 42
Accuracy : 0.86
95% CI : (0.8221, 0.8925)
No Information Rate : 0.8
P-Value [Acc > NIR] : 0.001145
Kappa : 0.5172
Mcnemar's Test P-Value : 0.011118
Sensitivity : 0.5250
Specificity : 0.9437
Pos Pred Value : 0.7000
Neg Pred Value : 0.8882
Prevalence : 0.2000
Detection Rate : 0.1050
Detection Prevalence : 0.1500
Balanced Accuracy : 0.7344
'Positive' Class : Suspeito
A função discriminante quadrática apresentou acurácia global de 86%, superior ao No Information Rate (0,80), indicando capacidade preditiva significativa. A sensibilidade foi de 0,525, mostrando melhora discreta na identificação de casos suspeitos em comparação ao desempenho típico de classificadores lineares quando há heterogeneidade nas covariâncias. Por outro lado, a especificidade foi ligeiramente menor (0,9437), sugerindo pequeno aumento de erros na classificação de indivíduos da classe Regular. O coeficiente Kappa (0,5172) indica concordância moderada, enquanto a acurácia balanceada (0,7344) mostra desempenho relativamente equilibrado entre as classes, apesar do desbalanceamento amostral. Em termos gerais, o modelo quadrático apresenta desempenho semelhante ao linear, com leve ganho na detecção da classe Suspeito, porém sem melhoria substancial na acurácia global.
5.2 Método da Ressubstituição com Divisão Amostral
set.seed(12345)train_id <-createDataPartition(df$classe, p =0.7, list =FALSE)train <- df[train_id, ]test <- df[-train_id, ]
Foi realizada uma divisão amostral estratificada utilizando a função createDataPartition(), preservando a proporção original das classes Regular e Suspeito em ambos os subconjuntos. Fixou-se uma semente aleatória (set.seed(12345)) para garantir reprodutibilidade dos resultados. Aproximadamente 70% das observações foram alocadas ao conjunto de treinamento (train), utilizado para ajuste dos modelos discriminantes, enquanto os 30% restantes compuseram o conjunto de teste (test), empregado na avaliação externa do desempenho preditivo.
prop.table(table(df$classe))
Regular Suspeito
0.8 0.2
prop.table(table(train$classe))
Regular Suspeito
0.8 0.2
prop.table(table(test$classe))
Regular Suspeito
0.8 0.2
A divisão amostral foi realizada de forma estratificada em relação à variável resposta, preservando a proporção original das classes no conjunto completo de dados. Observa-se que a classe Regular representa aproximadamente 80% das observações, enquanto a classe Suspeito corresponde a cerca de 20%, padrão que se manteve tanto nos conjuntos de treinamento quanto de teste. Essa manutenção das proporções indica que o particionamento não introduziu viés na representação das populações, garantindo maior confiabilidade na estimação dos modelos discriminantes e na avaliação de desempenho fora da amostra.
Antes da estimação das funções discriminantes, as variáveis explicativas foram padronizadas por meio de centralização e escalonamento, utilizando exclusivamente as estatísticas do conjunto de treinamento. Essa estratégia evita vazamento de informação entre as amostras e garante que a avaliação do modelo no conjunto de teste reflita um cenário realista de aplicação. Posteriormente, a mesma transformação foi aplicada ao conjunto de teste, assegurando consistência na escala das variáveis durante o processo de classificação.
fit_lda <-lda(classe ~ ., data = train_scaled)fit_lda
A análise discriminante linear foi estimada utilizando as variáveis padronizadas, o que permite interpretar diretamente os coeficientes da função discriminante como medidas relativas da contribuição de cada variável para a separação entre as populações. As probabilidades a priori indicam um desbalanceamento entre as classes, com aproximadamente 80% das observações pertencendo ao grupo Regular e 20% ao grupo Suspeito.
Observa-se que os centróides das populações ao longo das variáveis padronizadas apresentam sinais opostos, sugerindo que o grupo Suspeito tende a assumir valores mais elevados nas variáveis analisadas, especialmente em valor_reparo, ratio_reparo_vs_fipe, dias_para_reportar e mudancas_contato_6m, o que indica um padrão comportamental distinto entre os grupos.
A função discriminante linear (LD1) evidencia que as variáveis com maior contribuição para a separação entre as classes são:
ratio_reparo_vs_fipe (0,638): principal fator discriminante;
valor_reparo (0,552): forte influência na classificação;
dias_para_reportar (0,232) e mudancas_contato_6m (0,204): contribuição moderada.
Por outro lado, as variáveis qt_sinistros_12m (0,083) e dist_evento_resid (\(\approx\) 0,003) apresentam menor impacto discriminante, indicando que exercem influência limitada na distinção entre as populações no espaço linear.
De forma geral, a padronização das variáveis permite concluir que a separação entre os grupos é dominada por características associadas ao custo relativo do reparo e ao comportamento temporal do segurado, sugerindo que padrões financeiros e operacionais são mais relevantes para a discriminação do que medidas puramente espaciais.
Confusion Matrix and Statistics
Reference
Prediction Regular Suspeito
Regular 92 13
Suspeito 4 11
Accuracy : 0.8583
95% CI : (0.7829, 0.9153)
No Information Rate : 0.8
P-Value [Acc > NIR] : 0.06473
Kappa : 0.4848
Mcnemar's Test P-Value : 0.05235
Sensitivity : 0.45833
Specificity : 0.95833
Pos Pred Value : 0.73333
Neg Pred Value : 0.87619
Prevalence : 0.20000
Detection Rate : 0.09167
Detection Prevalence : 0.12500
Balanced Accuracy : 0.70833
'Positive' Class : Suspeito
A avaliação da função discriminante linear no conjunto de teste indica um desempenho global satisfatório, com acurácia de 85,83%, valor superior à taxa base de classificação (No Information Rate = 0,80). O intervalo de confiança de 95% sugere estabilidade razoável da estimativa, embora o p-valor associado à comparação com a NIR (p = 0,0647) indique evidência estatística apenas moderada de melhoria em relação a uma classificação trivial.
A matriz de confusão revela que o modelo apresenta alta especificidade (95,83%), indicando excelente capacidade de identificar corretamente contratos do grupo Regular. Entretanto, a sensibilidade (45,83%) é relativamente baixa, evidenciando dificuldade em detectar observações do grupo Suspeito. Esse padrão é coerente com o desbalanceamento entre as classes e sugere que a fronteira linear favorece a redução de falsos positivos em detrimento da identificação completa dos casos suspeitos.
O coeficiente Kappa (0,4848) e a acurácia balanceada (0,7083) indicam desempenho moderado quando se considera o desequilíbrio entre as populações. Além disso, o teste de McNemar (p ≈ 0,052) sugere uma leve assimetria nos erros de classificação, com tendência a subestimar a classe Suspeito.
De forma geral, os resultados mostram que a função discriminante linear apresenta boa capacidade de classificação global, porém com limitação na detecção de casos suspeitos, indicando que ajustes na fronteira de decisão ou estratégias de balanceamento podem ser considerados para melhorar a sensibilidade do modelo.
5.2.2 Análise Discriminante Quadrática (QDA)
fit_qda <-qda(classe ~ ., data = train_scaled)fit_qda
O ajuste da função discriminante quadrática indica diferenças claras entre os centróides das duas populações no espaço das variáveis padronizadas. Observa-se que o grupo Suspeito apresenta médias sistematicamente superiores em praticamente todas as variáveis analisadas, especialmente em ratio_reparo_vs_fipe, valor_reparo, dias_para_reportar e mudancas_contato_6m. Esse padrão sugere maior intensidade de sinistros, maior tempo de reporte e valores relativos de reparo mais elevados, características coerentes com perfis de maior risco.
Como as variáveis foram padronizadas previamente, os valores médios negativos associados ao grupo Regular indicam posicionamento abaixo da média global, enquanto as médias positivas do grupo Suspeito indicam deslocamento na direção oposta. Essa separação dos centróides evidencia que existe discriminação potencial entre as classes, embora não necessariamente linear.
A principal diferença conceitual do QDA em relação à LDA é a consideração de matrizes de covariância específicas para cada população, permitindo que a fronteira de decisão seja curva. Dessa forma, o modelo torna-se mais flexível para capturar diferenças na dispersão e na estrutura de variância entre os grupos, aspecto particularmente relevante quando há evidência de heterogeneidade nas matrizes de covariância.
Em síntese, os resultados sugerem que a separação entre as classes ocorre tanto por deslocamento das médias quanto por diferenças na estrutura de variabilidade, justificando a utilização da abordagem quadrática como alternativa à função discriminante linear.
Confusion Matrix and Statistics
Reference
Prediction Regular Suspeito
Regular 91 12
Suspeito 5 12
Accuracy : 0.8583
95% CI : (0.7829, 0.9153)
No Information Rate : 0.8
P-Value [Acc > NIR] : 0.06473
Kappa : 0.5029
Mcnemar's Test P-Value : 0.14561
Sensitivity : 0.5000
Specificity : 0.9479
Pos Pred Value : 0.7059
Neg Pred Value : 0.8835
Prevalence : 0.2000
Detection Rate : 0.1000
Detection Prevalence : 0.1417
Balanced Accuracy : 0.7240
'Positive' Class : Suspeito
A matriz de confusão obtida no conjunto de teste indica que o modelo QDA apresentou acurácia global de aproximadamente 85,8%, valor superior à taxa de classificação aleatória (NIR = 0,8), embora o teste estatístico associado apresente evidência moderada de ganho preditivo. Observa-se elevada especificidade (\(\approx\) 0,95), indicando que a maioria dos clientes regulares foi corretamente identificada. Por outro lado, a sensibilidade (\(\approx\) 0,50) foi mais baixa, revelando maior dificuldade do modelo em detectar corretamente observações da classe Suspeito, o que sugere uma tendência conservadora na classificação.
O coeficiente Kappa em torno de 0,50 indica concordância moderada além do acaso, reforçando que o modelo possui capacidade discriminante, mas ainda apresenta limitações na identificação da classe minoritária. A balanced accuracy próxima de 0,72 evidencia que o desempenho não é uniforme entre as classes, refletindo o desequilíbrio amostral existente. De modo geral, os resultados sugerem que a função discriminante quadrática captura parte da estrutura multivariada dos dados, porém com ganhos modestos na capacidade de detecção da classe positiva, mantendo um comportamento mais eficiente na classificação da classe Regular.
5.3 Método da Validação Cruzada \(k\)-fold
5.3.1 Análise Discriminante Linear (LDA)
train_control <-trainControl(method ="cv", number =10)lda_cv <-train(classe ~ ., data = train_scaled, method ="lda", trControl = train_control)lda_cv$finalModel
A estimação da função discriminante linear via validação cruzada (10-fold CV) produziu coeficientes estáveis e consistentes com aqueles obtidos na estimação direta do modelo. Observa-se que as variáveis ratio_reparo_vs_fipe e valor_reparo apresentam os maiores pesos positivos na função discriminante, indicando maior contribuição para a separação entre as populações. A variável dias_para_reportar também exerce influência relevante, sugerindo que atrasos no reporte tendem a deslocar as observações na direção associada à classe Suspeito.
Por outro lado, dist_evento_resid apresenta coeficiente pequeno, indicando menor poder discriminante marginal quando consideradas simultaneamente as demais variáveis. A estabilidade dos coeficientes sob validação cruzada sugere que a estrutura de separação entre os grupos é consistente e pouco sensível a variações amostrais, reforçando a robustez do modelo linear estimado.
5.3.1.1 Avaliação do Modelo Linear
lda_cv$results
A avaliação do modelo discriminante linear por meio de validação cruzada (10 folds) indicou uma acurácia média de aproximadamente 0,86, com coeficiente Kappa em torno de 0,49, sugerindo desempenho moderado na classificação além do acaso. O desvio padrão da acurácia (\(\approx\) 0,053) indica variação relativamente pequena entre as partições amostrais, evidenciando estabilidade do modelo frente a diferentes subconjuntos de treinamento e teste.
Esses resultados mostram que a função discriminante linear apresenta capacidade consistente de separação entre as classes, mantendo desempenho semelhante ao observado nas demais estratégias de avaliação, mas com estimativa mais realista do erro de generalização. O valor positivo de Kappa reforça que o modelo captura estrutura discriminante relevante nos dados, embora ainda existam regiões de sobreposição entre as populações que limitam uma classificação perfeita.
A análise discriminante quadrática foi estimada considerando probabilidades a priori proporcionais ao tamanho das classes (Regular = 0,8; Suspeito = 0,2). As médias padronizadas indicam que a classe Suspeito apresenta valores sistematicamente maiores na maioria das variáveis, sugerindo deslocamento multivariado consistente entre os grupos. Diferentemente da LDA, a QDA permite estruturas de covariância distintas entre as populações, resultando em fronteiras de decisão potencialmente não lineares.
Apesar dessa maior flexibilidade teórica, os coeficientes médios estimados nas partições de validação cruzada mostram comportamento semelhante ao modelo linear, sugerindo que a separação entre classes ocorre predominantemente ao longo de uma direção principal comum no espaço das variáveis. Isso indica que a complexidade adicional da QDA pode não trazer ganhos substanciais de generalização neste conjunto de dados.
5.3.2.1 Avaliação do Modelo Quadrático
qda_cv$results
A análise discriminante quadrática apresentou acurácia média de aproximadamente 0,84 na validação cruzada (Kappa\(\approx\) 0,42), indicando capacidade moderada de discriminação entre as classes. O desvio-padrão relativamente elevado da acurácia (\(\approx\) 0,05) sugere maior variabilidade do modelo entre as partições amostrais, refletindo a maior complexidade da QDA ao estimar matrizes de covariância específicas para cada grupo. Comparativamente, observa-se que o desempenho preditivo não supera substancialmente o obtido pela função discriminante linear, apesar da flexibilização da fronteira de decisão. Esse resultado indica que, embora as populações apresentem diferenças estruturais nas covariâncias, a separação entre classes ocorre predominantemente ao longo de uma direção linear dominante, tornando o modelo linear mais estável e parcimonioso para fins de classificação.
6 Conclusão
A análise exploratória inicial evidenciou diferenças sistemáticas entre as populações Regular e Suspeito, tanto nas distribuições marginais das variáveis quanto nas relações bivariadas e estruturas de correlação. As visualizações gráficas indicaram que a classe Suspeito tende a apresentar valores mais elevados em indicadores associados a risco, como razão reparo/FIPE, quantidade de sinistros e distância do evento à residência, além de maior dispersão geral. A projeção em componentes principais confirmou a existência de uma direção dominante de separação entre os grupos, embora com região de sobreposição relevante, sugerindo a presença de erros de classificação inevitáveis.
O teste de Box indicou heterogeneidade significativa entre as matrizes de covariância, evidenciando que a hipótese de igualdade estrutural entre os grupos não é estritamente válida. Ainda assim, a análise discriminante linear apresentou desempenho competitivo e estável, com boa capacidade de separação ao longo de uma única função discriminante dominante (LD1). A interpretação dos coeficientes revelou que variáveis associadas ao comportamento de sinistros e ao valor relativo do reparo possuem maior contribuição para a discriminação entre as classes.
A análise discriminante quadrática, por sua vez, incorporou a diferença nas estruturas de variância entre os grupos, permitindo fronteiras de decisão mais flexíveis. Entretanto, os resultados empíricos mostraram ganhos limitados em relação ao modelo linear, além de maior variabilidade nas estimativas durante a validação cruzada. Isso sugere que, apesar da diferença nas covariâncias, a separação entre as populações ocorre principalmente em uma direção aproximadamente linear no espaço das variáveis.
De modo geral, os resultados indicam que ambos os modelos apresentam desempenho satisfatório na identificação da classe Suspeito, com níveis semelhantes de acurácia e concordância (Kappa). Contudo, considerando a maior estabilidade, simplicidade interpretativa e menor variância preditiva observada, a função discriminante linear se mostra mais adequada como modelo final para classificação neste contexto.