Avaliação da Satisfação de Estudantes Universitários
1 Contexto e Objetivo
Uma universidade realizou uma pesquisa institucional com 250 estudantes de graduação, solicitando que atribuíssem escores de 0 a 10 para diferentes aspectos relacionados à sua experiência acadêmica no campus.
O objetivo da pesquisa é identificar dimensões latentes de satisfação, permitindo que a gestão universitária compreenda quais fatores estruturais e acadêmicos influenciam a percepção geral dos estudantes.
As variáveis analisadas são:
TEACH – qualidade do ensino
CURRIC – organização curricular
FACULTY – acessibilidade dos professores
INFRA – infraestrutura do campus
LIBRARY – qualidade da biblioteca
IT – serviços de tecnologia/internet
SUPPORT – serviços administrativos e apoio ao estudante
TEACH CURRIC FACULTY INFRA
Min. : 0.000 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 3.732 1st Qu.: 3.764 1st Qu.: 3.948 1st Qu.: 3.707
Median : 5.109 Median : 4.940 Median : 4.932 Median : 5.257
Mean : 5.006 Mean : 5.001 Mean : 5.001 Mean : 4.994
3rd Qu.: 6.462 3rd Qu.: 6.352 3rd Qu.: 6.232 3rd Qu.: 6.242
Max. :10.000 Max. :10.000 Max. :10.000 Max. :10.000
LIBRARY IT SUPPORT
Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 3.631 1st Qu.: 3.777 1st Qu.: 3.589
Median : 4.996 Median : 4.845 Median : 4.954
Mean : 5.002 Mean : 5.000 Mean : 4.997
3rd Qu.: 6.284 3rd Qu.: 6.451 3rd Qu.: 6.360
Max. :10.000 Max. :10.000 Max. :10.000
A base de dados contém 250 observações e 7 variáveis numéricas, todas armazenadas como dbl, correspondendo às avaliações de satisfação dos estudantes em escala contínua de 0 a 10. Não há variáveis categóricas nem valores ausentes aparentes, o que facilita a aplicação direta de métodos baseados em matriz de correlação, como PCA e Análise Fatorial Exploratória.
Em média, os estudantes atribuem avaliações moderadas a todos os aspectos analisados. Não há evidência de satisfação extrema nem de insatisfação generalizada. Os quartis mostram ampla dispersão:
1º quartil geralmente entre 3.6 e 3.9
3º quartil geralmente entre 6.2 e 6.4
Isso indica que:
Há heterogeneidade real entre estudantes;
Diferentes perfis de satisfação coexistem na amostra.
Análise fatorial exige variabilidade. Se todos os estudantes atribuíssem notas muito semelhantes, não haveria estrutura de correlação suficiente para extrair fatores.
A análise descritiva inicial indica que as variáveis apresentam comportamento adequado para a aplicação de técnicas multivariadas baseadas em correlação. Todas as variáveis respeitam a escala proposta, exibem variabilidade suficiente, não apresentam concentrações excessivas em valores extremos e possuem distribuições aproximadamente simétricas. Dessa forma, a base de dados é apropriada para a aplicação da Análise Fatorial Exploratória.
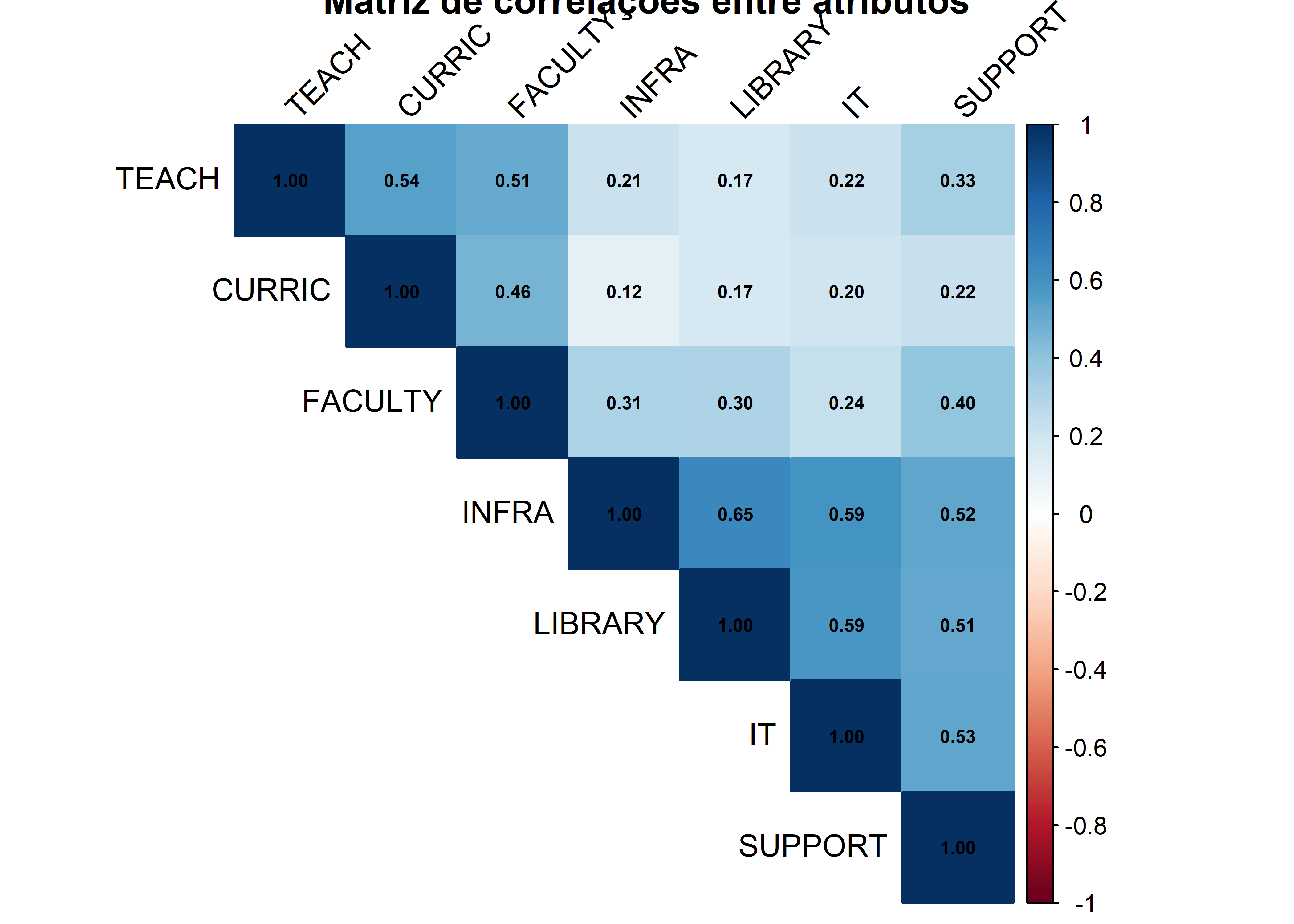
A matriz de correlação entre as sete variáveis evidencia padrões claros de associação, sugerindo a presença de estruturas latentes passíveis de modelagem por meio de Análise de Componentes Principais e Análise Fatorial Exploratória.
As variáveis TEACH, CURRIC e FACULTY apresentam correlações moderadas a elevadas entre si:
TEACH × CURRIC: 0,54
TEACH × FACULTY: 0,51
CURRIC × FACULTY: 0,46
Essas correlações indicam que estudantes que avaliam positivamente um desses aspectos acadêmicos tendem a avaliar positivamente os demais, sugerindo a existência de um fator comum associado à Qualidade Acadêmica.
Do ponto de vista da análise fatorial, esse padrão é típico de um conjunto de variáveis que compartilham variância comum, condição essencial para a extração de fatores.
As variáveis INFRA, LIBRARY e IT apresentam correlações elevadas entre si, destacando-se:
INFRA × LIBRARY: 0,65
INFRA × IT: 0,59
LIBRARY × IT: 0,59
Esses valores indicam uma forte associação entre aspectos de infraestrutura física e tecnológica do campus, sugerindo a presença de um fator latente relacionado à Estrutura e Recursos Institucionais.
Esse bloco de correlações é mais intenso do que o observado no bloco acadêmico, o que sugere que essa dimensão pode ser particularmente bem definida na estrutura fatorial.
A variável SUPPORT apresenta correlações moderadas com ambos os blocos:
Com variáveis acadêmicas:
SUPPORT × TEACH: 0,33
SUPPORT × FACULTY: 0,40
Com variáveis estruturais:
SUPPORT × INFRA: 0,52
SUPPORT × LIBRARY: 0,51
SUPPORT × IT: 0,53
Esse padrão sugere que SUPPORT possui uma natureza híbrida, relacionada tanto à experiência acadêmica quanto ao suporte institucional. Em termos de análise fatorial, isso antecipa a possibilidade de cargas cruzadas (cross-loading), isto é, a variável apresentar cargas relevantes em mais de um fator.
Esse comportamento não representa um problema metodológico, desde que seja substantivamente justificável, como é o caso neste contexto.
As correlações entre variáveis acadêmicas e estruturais são, em geral, baixas a moderadas, por exemplo:
TEACH × INFRA: 0,21
CURRIC × INFRA: 0,12
FACULTY × IT: 0,24
Esses valores indicam que, embora as dimensões acadêmica e estrutural estejam relacionadas, elas não são redundantes, o que reforça a hipótese de mais de um fator latente.
corrplot(cor_mat, method ="color", type ="upper", addCoef.col ="black",tl.col ="black", tl.srt =45, number.cex = .6,title ="Matriz de correlações entre atributos")
O gráfico apresenta o mapa de calor da matriz de correlações entre os atributos avaliados pelos estudantes, no qual a intensidade da cor azul indica maior associação positiva entre as variáveis, enquanto cores mais claras indicam associações fracas.
De modo geral, observa-se a presença de padrões bem definidos de correlação, sugerindo uma estrutura latente adequada para aplicação de Análise Fatorial Exploratória.
5 Adequação para Análise Fatorial: KMO e Bartlett
Antes da aplicação da Análise Fatorial Exploratória, avaliou-se a adequação da matriz de correlações por meio da Medida de Adequação da Amostra de Kaiser–Meyer–Olkin (KMO) e do Teste de Esfericidade de Bartlett.
KMO(cor_mat)
Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = cor_mat)
Overall MSA = 0.8
MSA for each item =
TEACH CURRIC FACULTY INFRA LIBRARY IT SUPPORT
0.74 0.71 0.81 0.80 0.81 0.83 0.87
O valor global da medida KMO foi:
\[KMO=0,80\]
De acordo com a classificação proposta por Kaiser, valores de KMO entre 0,80 e 0,89 são considerados muito bons, indicando que a proporção de variância comum entre as variáveis é elevada.
Além disso, as medidas individuais (MSA) para cada variável foram:
Variável
MSA
TEACH
0,74
CURRIC
0,71
FACULTY
0,81
INFRA
0,80
LIBRARY
0,81
IT
0,83
SUPPORT
0,87
Todas as variáveis apresentam MSA superiores a 0,70, indicando que nenhuma delas compromete a estrutura fatorial.
A variável SUPPORT apresenta o maior valor de MSA (0,87), sugerindo que ela compartilha uma quantidade considerável de variância com as demais variáveis, apesar de seu caráter transversal.
Não há necessidade de remoção de variáveis com base na medida KMO.
Do ponto de vista metodológico, esses resultados indicam que os dados apresentam correlações parciais relativamente pequenas, condição desejável para a extração de fatores comuns.
O teste de Bartlett produziu os seguintes resultados:
Estatística qui-quadrado: \(\chi^2 =619,41\)
Graus de liberdade: \(df = 21\)
Valor-p: \(p<0,001\)
O valor-p extremamente pequeno leva à rejeição da hipótese nula de que a matriz de correlações populacional é a matriz identidade. Isso indica que existem correlações significativas entre as variáveis, condição essencial para a aplicação da análise fatorial.
Os resultados da medida KMO e do teste de esfericidade de Bartlett indicam que a matriz de correlações apresenta adequação muito boa para a aplicação da análise fatorial. Assim, procede-se à determinação do número de fatores a serem retidos e à estimação dos modelos por diferentes métodos, visando comparar soluções alternativas e avaliar a robustez da estrutura latente identificada.
6 Quantos fatores reter?
A determinação do número de fatores a serem retidos foi realizada com base em múltiplos critérios, conforme recomendado na literatura, evitando decisões baseadas em um único procedimento.
De acordo com o critério de Kaiser, devem ser retidos os fatores com autovalores superiores a 1. Assim, esse critério sugere a retenção de dois fatores, uma vez que apenas os dois primeiros autovalores satisfazem essa condição.
Do ponto de vista interpretativo, os dois primeiros fatores concentram a maior parte da variância total padronizada, enquanto os fatores subsequentes apresentam contribuições marginais, indicando que a estrutura essencial dos dados pode ser adequadamente representada por duas dimensões latentes.
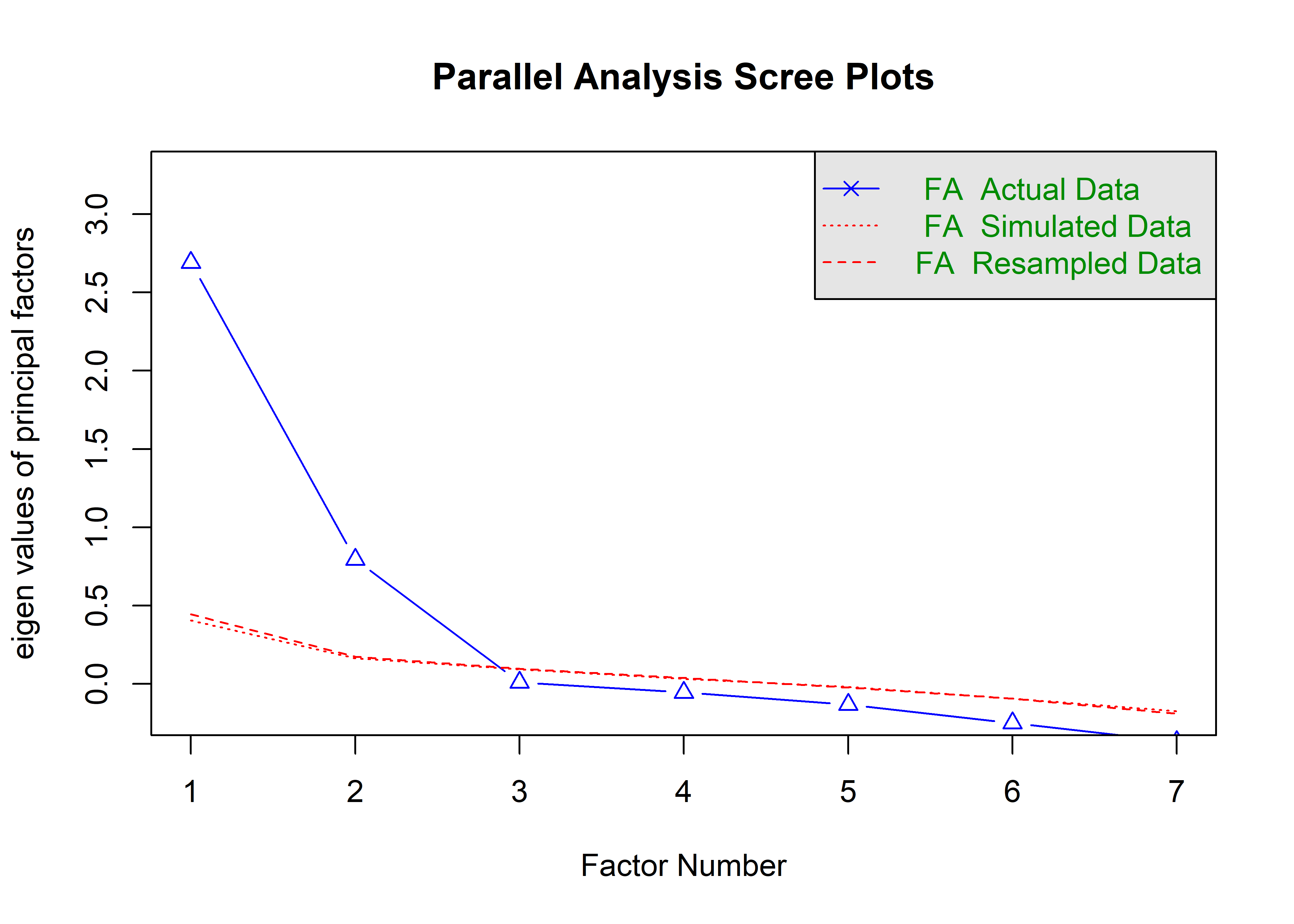
6.2 Scree Plot
A inspeção visual do Scree Plot evidencia um ponto de inflexão pronunciado após o segundo fator, a partir do qual os autovalores passam a decrescer de forma aproximadamente linear e com pequena magnitude.
Esse padrão sugere que os fatores a partir do terceiro capturam predominantemente variância específica ou ruído, reforçando a escolha de dois fatores como solução parcimoniosa.
6.3 Análise Paralela
A análise paralela compara os autovalores observados com aqueles obtidos a partir de dados aleatórios simulados com a mesma dimensão da base original.
Observa-se que:
Os dois primeiros autovalores empíricos são claramente superiores aos autovalores provenientes dos dados simulados;
A partir do terceiro fator, os autovalores observados tornam-se inferiores aos autovalores simulados.
Segundo esse critério, apenas os dois primeiros fatores apresentam evidência estatística de estrutura não aleatória, corroborando a retenção de dois fatores.
Principal Components Analysis
Call: principal(r = dados, nfactors = 2, rotate = "varimax", scores = TRUE)
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com
TEACH 0.13 0.83 0.71 0.29 1.0
CURRIC 0.05 0.83 0.69 0.31 1.0
FACULTY 0.28 0.74 0.63 0.37 1.3
INFRA 0.85 0.09 0.73 0.27 1.0
LIBRARY 0.84 0.09 0.72 0.28 1.0
IT 0.81 0.11 0.68 0.32 1.0
SUPPORT 0.71 0.31 0.61 0.39 1.4
RC1 RC2
SS loadings 2.70 2.06
Proportion Var 0.39 0.29
Cumulative Var 0.39 0.68
Proportion Explained 0.57 0.43
Cumulative Proportion 0.57 1.00
Mean item complexity = 1.1
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.09
with the empirical chi square 78.37 with prob < 1e-13
Fit based upon off diagonal values = 0.95
print(AF_pca$loadings, cutoff =0.30)
Loadings:
RC1 RC2
TEACH 0.834
CURRIC 0.827
FACULTY 0.743
INFRA 0.850
LIBRARY 0.841
IT 0.814
SUPPORT 0.715 0.309
RC1 RC2
SS loadings 2.699 2.057
Proportion Var 0.386 0.294
Cumulative Var 0.386 0.679
O método das Componentes Principais foi aplicada à matriz de correlações das variáveis, considerando a extração de dois fatores, conforme indicado pelos critérios de Kaiser, Scree Plot e Análise Paralela. Utilizou-se rotação Varimax, com o objetivo de facilitar a interpretação das componentes.
7.1.1 Cargas fatoriais
A Tabela a seguir apresenta as cargas padronizadas das variáveis nas duas componentes principais, bem como as comunalidades (\(h^2\)), unicidades (\(u^2\)) e complexidade.
Variável
RC1
RC2
\(h^2\)
\(u^2\)
TEACH
0,13
0,83
0,71
0,29
CURRIC
0,05
0,83
0,69
0,31
FACULTY
0,28
0,74
0,63
0,37
INFRA
0,85
0,09
0,73
0,27
LIBRARY
0,84
0,09
0,72
0,28
IT
0,81
0,11
0,68
0,32
SUPPORT
0,71
0,31
0,61
0,39
Observa-se que:
O Fator 1 (RC1) apresenta cargas elevadas para INFRA, LIBRARY, IT e SUPPORT, caracterizando uma dimensão associada à Estrutura e Suporte Institucional;
O Fator 2 (RC2) apresenta cargas elevadas para TEACH, CURRIC e FACULTY, caracterizando uma dimensão associada à Qualidade Acadêmica;
A variável SUPPORT apresenta carga relevante no Fator 1 e carga secundária no Fator 2, refletindo sua natureza transversal.
7.1.2 Variância Explicada
A decomposição da variância total é apresentada a seguir:
Componente
SS Loadings
Proporção da Variância
Variância Acumulada
RC1
2,70
0,39
0,39
RC2
2,06
0,29
0,68
As duas componentes explicam conjuntamente aproximadamente 68% da variância total, o que é considerado um valor elevado em aplicações nas ciências sociais.
Além disso, observa-se que:
O primeiro fator responde por cerca de 39% da variância;
O segundo fator adiciona aproximadamente 29%;
A distribuição da variância é relativamente equilibrada entre as componentes.
7.1.3 Comunalidades e Complexidade
As comunalidades (\(h^2\)) variam entre 0,61 e 0,73, indicando que todas as variáveis são bem representadas pela solução com dois fatores.
A complexidade média dos itens é aproximadamente 1,1, sugerindo que:
A maioria das variáveis apresenta carga dominante em apenas uma componente;
A estrutura resultante é simples e facilmente interpretável;
Não há evidência de componentes mal definidas ou altamente sobrepostas.
7.1.4 Qualidade de Ajuste da Solução
A qualidade de ajuste da solução com dois fatores pode ser avaliada por meio dos resíduos:
RMSR (Root Mean Square of Residuals) = 0,09
Qui-quadrado empírico = 78,37, com \(p < 10^{-13}\)
Ajuste baseado nos elementos fora da diagonal = 0,95
Esses resultados indicam que:
A magnitude média dos resíduos é relativamente pequena;
A solução reproduz adequadamente a estrutura de correlações observada;
Embora o teste qui-quadrado seja significativo (como esperado em amostras moderadas a grandes), os índices globais indicam bom ajuste prático.
7.2 Método dos Fatores Principais (PAF)
A Análise Fatorial Exploratória foi conduzida utilizando o método dos Fatores Principais (Principal Axis Factoring – PAF), com extração de dois fatores, conforme indicado pelos critérios de Kaiser, Scree Plot e Análise Paralela. Para facilitar a interpretação, aplicou-se rotação Varimax, assumindo fatores ortogonais.
AF_fp <-fa(dados, nfactors =2, fm ="pa", rotate ="varimax")print(AF_fp$loadings, cutoff =0.3)
Loadings:
PA1 PA2
TEACH 0.758
CURRIC 0.691
FACULTY 0.636
INFRA 0.796
LIBRARY 0.780
IT 0.727
SUPPORT 0.627 0.314
PA1 PA2
SS loadings 2.260 1.609
Proportion Var 0.323 0.230
Cumulative Var 0.323 0.553
7.2.1 Estrutura das Cargas Fatoriais
A Tabela a seguir apresenta as cargas fatoriais padronizadas das variáveis nos dois fatores extraídos, considerando apenas cargas com magnitude superior a 0,30.
Variável
PA1
PA2
TEACH
0,758
CURRIC
0,691
FACULTY
0,636
INFRA
0,796
LIBRARY
0,780
IT
0,727
SUPPORT
0,627
0,314
Observa-se uma estrutura simples e bem definida, na qual a maioria das variáveis apresenta carga elevada em apenas um fator.
7.2.2 Variância Explicada pelos Fatores
A variância explicada pelos fatores pode ser resumida conforme a tabela a seguir:
Fator
SS Loadings
Proporção da Variância
Variância Acumulada
PA1
2,260
0,323
0,323
PA2
1,609
0,230
0,553
Os dois fatores explicam conjuntamente aproximadamente 55,3% da variância comum, valor considerado adequado em estudos aplicados nas ciências sociais, especialmente quando se utiliza um modelo de fatores comuns.
Observa-se que:
O primeiro fator responde por cerca de 32,3% da variância comum;
O segundo fator adiciona aproximadamente 23,0%;
A distribuição da variância entre os fatores é relativamente equilibrada.
7.2.3 Comparação conceitual com a a solução usando o método das componentes principais
Em comparação com a solução obtida usando o método das componentes principais, a solução PAF apresenta:
Menor proporção de variância explicada;
Estrutura de cargas semelhante à da PCA, indicando estabilidade da dimensionalidade;
Interpretação substantiva consistente, reforçando a existência de duas dimensões latentes bem definidas.
Assim, a análise por Fatores Principais confirma que a estrutura identificada pela PCA não é um artefato da decomposição da variância total, mas reflete fatores comuns subjacentes às variáveis observadas.
7.3 Método da Máxima Verossimilhança
A Análise Fatorial Exploratória foi estimada utilizando o método da Máxima Verossimilhança (ML), com extração de dois fatores e rotação Varimax. Esse método permite, além da estimação das cargas fatoriais, a avaliação formal da qualidade de ajuste do modelo, sob a suposição de normalidade multivariada aproximada.
AF_ml <-fa(dados, nfactors =2, fm ="ml", rotate ="varimax", scores ="regression")AF_ml
Factor Analysis using method = ml
Call: fa(r = dados, nfactors = 2, rotate = "varimax", scores = "regression",
fm = "ml")
Standardized loadings (pattern matrix) based upon correlation matrix
ML1 ML2 h2 u2 com
TEACH 0.13 0.76 0.60 0.40 1.1
CURRIC 0.08 0.69 0.48 0.52 1.0
FACULTY 0.27 0.63 0.47 0.53 1.4
INFRA 0.80 0.12 0.65 0.35 1.0
LIBRARY 0.78 0.12 0.63 0.37 1.0
IT 0.72 0.15 0.55 0.45 1.1
SUPPORT 0.62 0.32 0.49 0.51 1.5
ML1 ML2
SS loadings 2.26 1.61
Proportion Var 0.32 0.23
Cumulative Var 0.32 0.55
Proportion Explained 0.58 0.42
Cumulative Proportion 0.58 1.00
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
df null model = 21 with the objective function = 2.52 with Chi Square = 619.41
df of the model are 8 and the objective function was 0.06
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 250 with the empirical chi square 5.91 with prob < 0.66
The total n.obs was 250 with Likelihood Chi Square = 13.92 with prob < 0.084
Tucker Lewis Index of factoring reliability = 0.974
RMSEA index = 0.054 and the 90 % confidence intervals are 0 0.101
BIC = -30.25
Fit based upon off diagonal values = 1
Measures of factor score adequacy
ML1 ML2
Correlation of (regression) scores with factors 0.91 0.86
Multiple R square of scores with factors 0.83 0.75
Minimum correlation of possible factor scores 0.66 0.49
print(AF_ml$loadings, cutoff =0.30)
Loadings:
ML1 ML2
TEACH 0.764
CURRIC 0.690
FACULTY 0.631
INFRA 0.797
LIBRARY 0.784
IT 0.724
SUPPORT 0.622 0.316
ML1 ML2
SS loadings 2.259 1.611
Proportion Var 0.323 0.230
Cumulative Var 0.323 0.553
7.3.1 Estrutura das Cargas Fatoriais
A Tabela a seguir apresenta as cargas fatoriais padronizadas, bem como as comunalidades (\(h^2\)), unicidades (\(u^2\)) e complexidade dos itens.
Variável
ML1
ML2
\(h^2\)
\(u^2\)
TEACH
0,13
0,76
0,60
0,40
CURRIC
0,08
0,69
0,48
0,52
FACULTY
0,27
0,63
0,47
0,53
INFRA
0,80
0,12
0,65
0,35
LIBRARY
0,78
0,12
0,63
0,37
IT
0,72
0,15
0,55
0,45
SUPPORT
0,62
0,32
0,49
0,51
Observa-se que a maioria das variáveis apresenta cargas elevadas em apenas um fator, caracterizando uma estrutura simples e facilmente interpretável. A variável SUPPORT apresenta carga principal no fator ML1 e carga secundária no fator ML2, indicando novamente seu caráter transversal.
7.3.2 Variância Explicada pelos Fatores
A decomposição da variância pode ser resumida conforme a tabela a seguir:
Fator
SS Loadings
Proporção da Variância
Variância Acumulada
ML1
2,26
0,32
0,32
ML2
1,61
0,23
0,55
Os dois fatores explicam conjuntamente cerca de 55% da variância comum, valor compatível com aplicações empíricas em ciências sociais e humanas.
7.3.3 Comparação com MCP e PAF
Comparativamente às soluções obtidas por MCP e PAF, o método de Máxima Verossimilhança:
Produz uma estrutura de cargas altamente consistente;
Confirma que a menor variância explicada em relação à MCP é esperada, pois apenas a variância comum é modelada.
Assim, a solução ML reforça a conclusão de que a estrutura identificada reflete fatores latentes reais, e não apenas artefatos da decomposição da variância total.
8 Interpretação dos Fatores
Com base no padrão das cargas fatoriais obtidas através na estimação do modelo fatorial utilizando o método da máxima verossimilhança, os fatores estimados podem ser interpretados da seguinte forma:
Fator 1 (ML1 – Estrutura e Suporte Institucional)
Apresenta cargas elevadas para INFRA, LIBRARY, IT e SUPPORT, representando aspectos relacionados à infraestrutura física, recursos tecnológicos e serviços administrativos de apoio ao estudante.
Fator 2 (ML2 – Qualidade Acadêmica)
Apresenta cargas elevadas para TEACH, CURRIC e FACULTY, caracterizando uma dimensão associada à qualidade do ensino, organização curricular e interação entre docentes e estudantes.
Essa interpretação é plenamente coerente com as soluções obtidas por MCP e PAF, indicando estabilidade da estrutura latente independentemente do método de estimação.
9 Conclusão
A análise identificou duas dimensões latentes de satisfação estudantil: Qualidade Acadêmica e Estrutura/Suporte Institucional. A comparação entre MCP, PAF e ML mostrou consistência geral na interpretação. Os escores fatoriais permitem análises adicionais, como segmentação de estudantes e priorização de políticas de melhoria institucional.