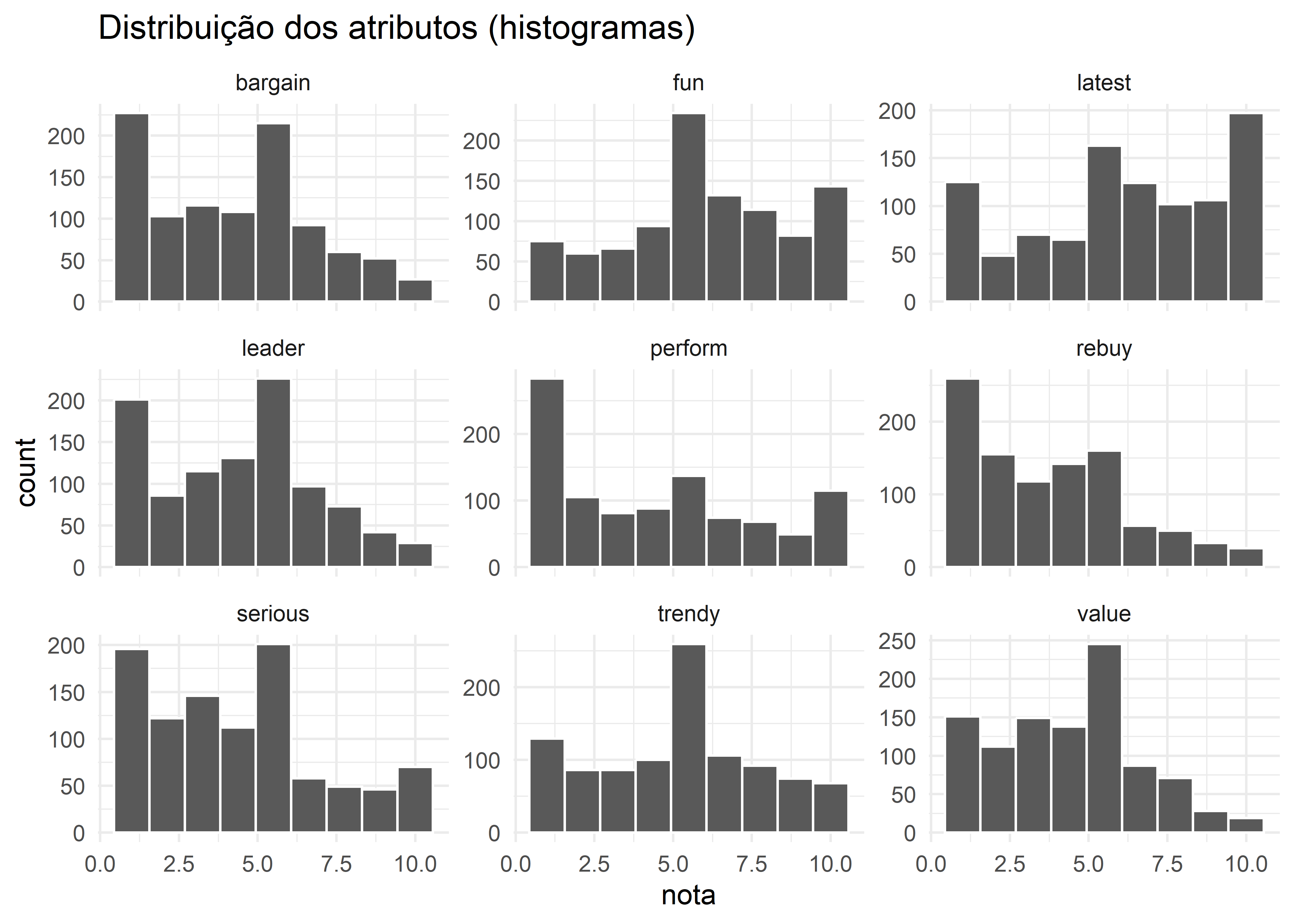
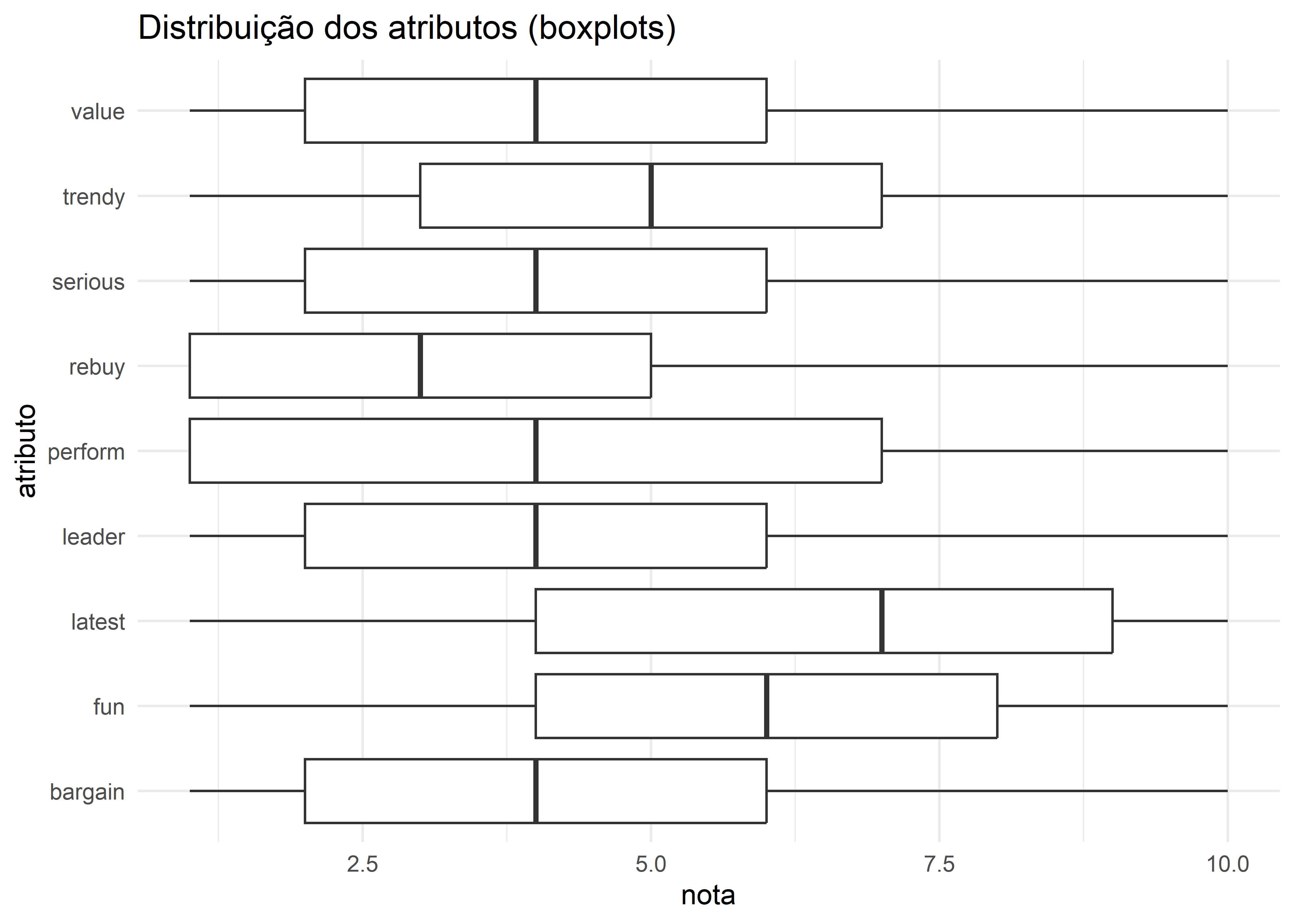
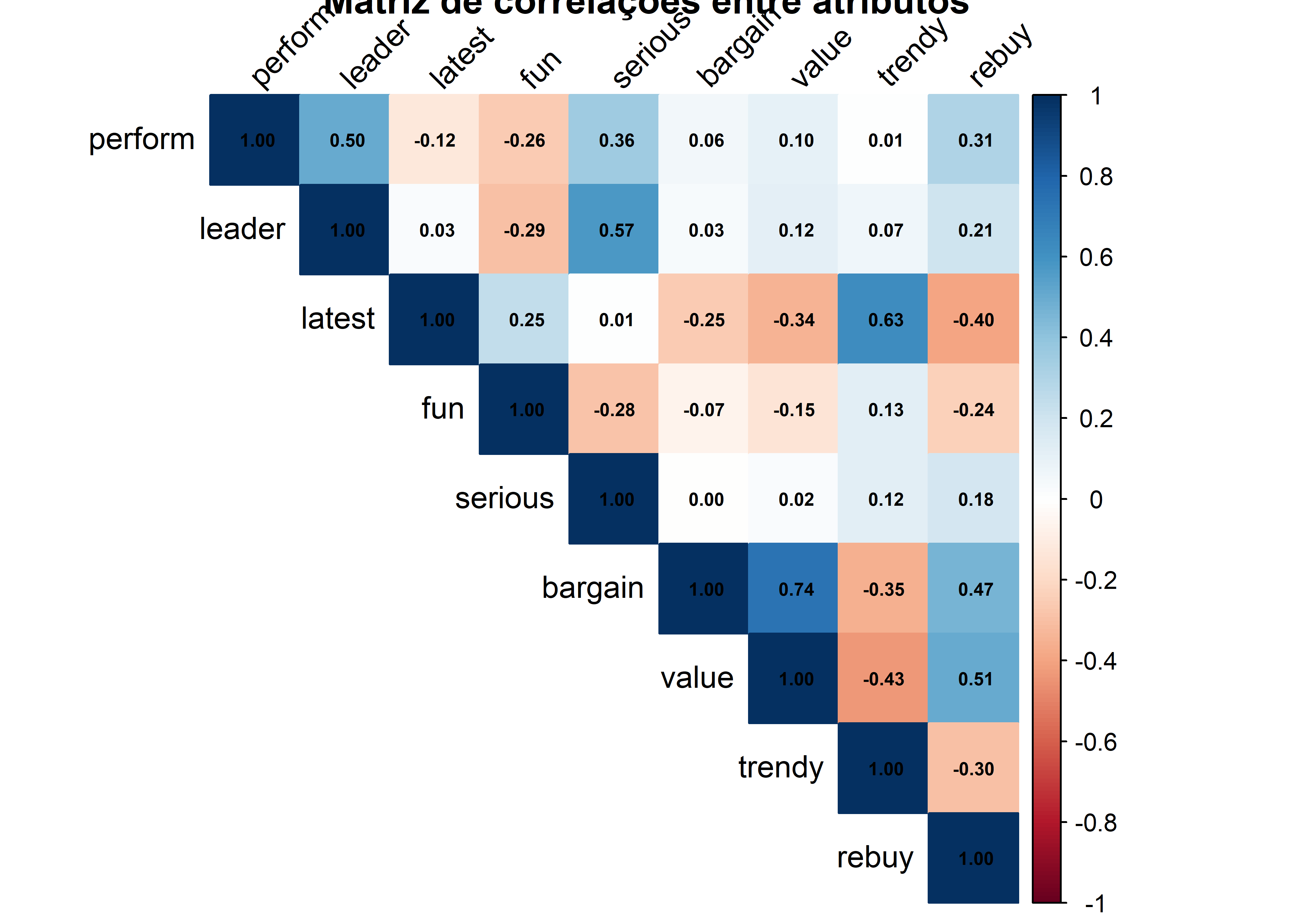
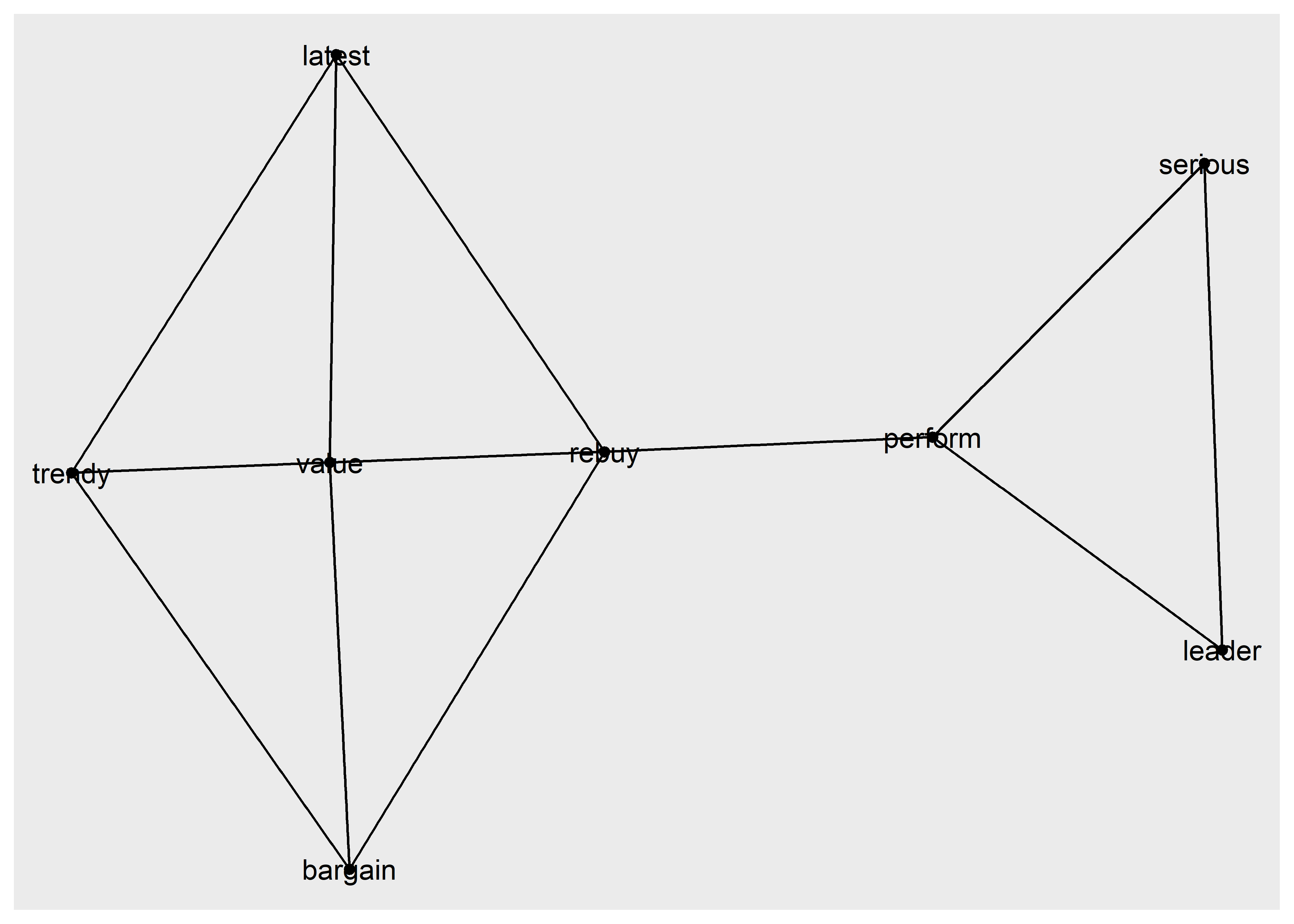
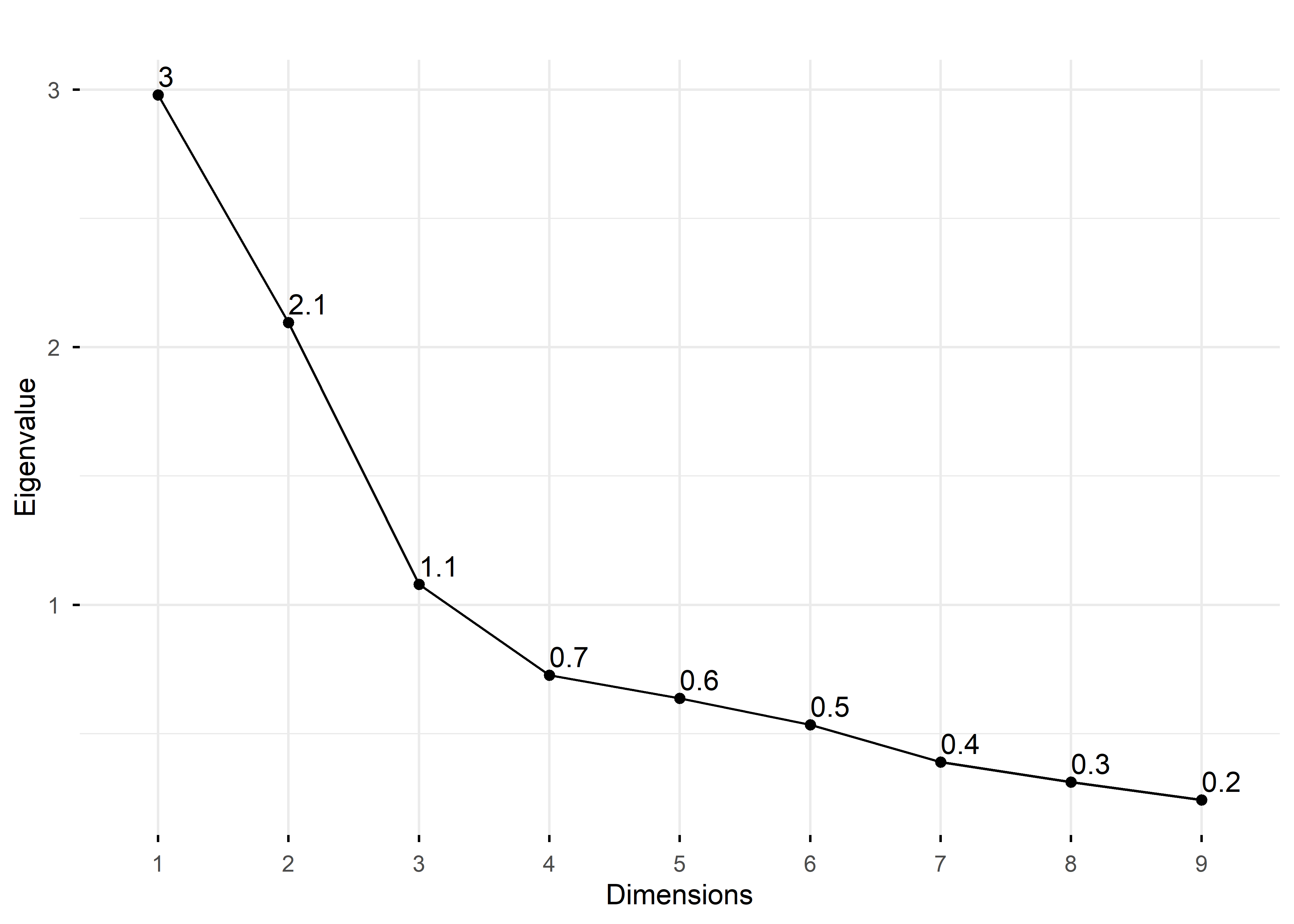
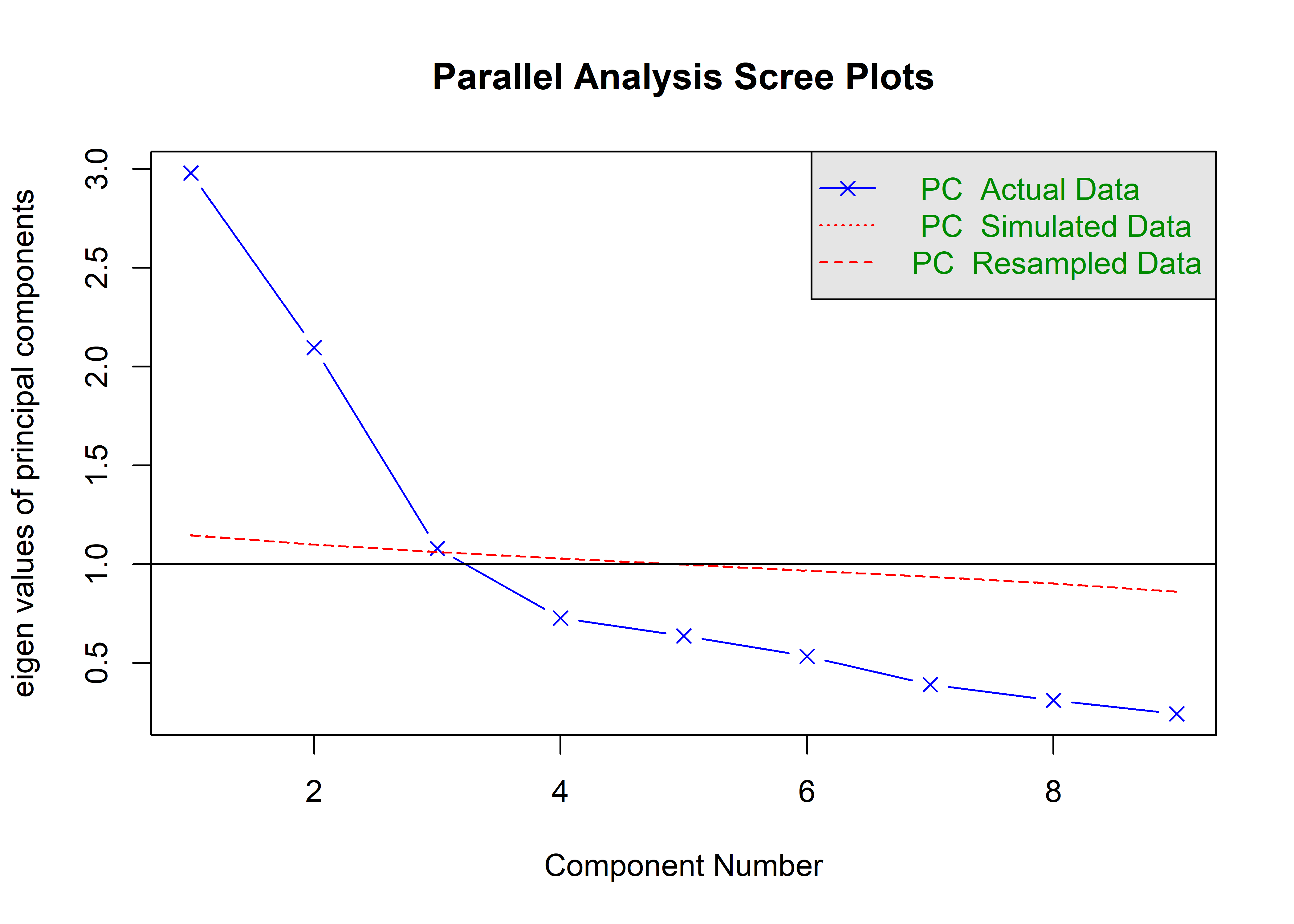
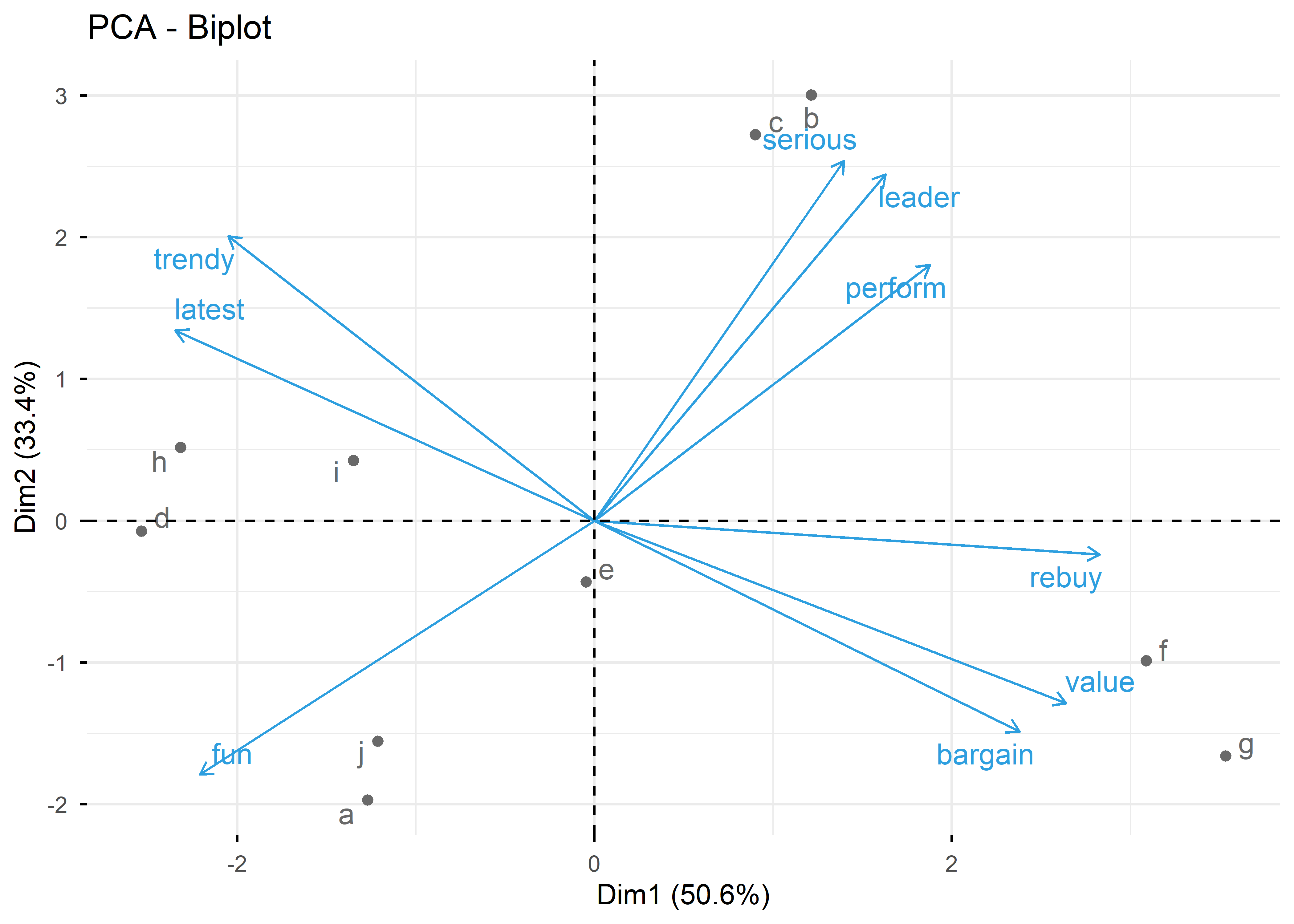
Rows: 1,000
Columns: 10
$ perform <dbl> 2, 1, 2, 1, 1, 2, 1, 2, 2, 3, 2, 1, 3, 1, 3, 3, 2, 3, 2, 2, 2,…
$ leader <dbl> 4, 1, 3, 6, 1, 8, 1, 1, 1, 1, 1, 2, 3, 5, 1, 2, 1, 8, 5, 3, 2,…
$ latest <dbl> 8, 4, 5, 10, 5, 9, 5, 7, 8, 9, 5, 7, 10, 7, 3, 7, 6, 9, 10, 9,…
$ fun <dbl> 8, 7, 9, 8, 8, 5, 7, 5, 10, 8, 6, 7, 10, 10, 6, 6, 7, 9, 8, 10…
$ serious <dbl> 2, 1, 2, 3, 1, 3, 1, 2, 1, 1, 1, 2, 1, 2, 1, 1, 2, 4, 2, 2, 1,…
$ bargain <dbl> 9, 1, 9, 4, 9, 8, 5, 8, 7, 3, 1, 3, 3, 1, 3, 10, 1, 7, 6, 2, 5…
$ value <dbl> 7, 1, 5, 5, 9, 7, 1, 7, 7, 3, 1, 2, 3, 3, 4, 5, 3, 10, 10, 6, …
$ trendy <dbl> 4, 2, 1, 2, 1, 1, 1, 7, 5, 4, 1, 1, 3, 3, 4, 1, 5, 4, 5, 5, 3,…
$ rebuy <dbl> 6, 2, 6, 1, 1, 2, 1, 1, 1, 1, 2, 5, 3, 1, 2, 3, 1, 2, 2, 2, 2,…
$ brand <chr> "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a", "a…